Automatic Deepfake Audio Detection Benchmark

Why we built it
Every audio deepfake vendor publishes an accuracy figure clustered around 99%. None of those numbers are comparable: each is computed on a test set the vendor controls, at a threshold the vendor controls, on attack distributions that may or may not mimic what an attacker would actually deploy in 2026.
The closest thing the field has to a public standard, ASVspoof 2019 LA, is a snapshot of TTS attacks that predates ElevenLabs, F5-TTS, Chatterbox, and the rest of the modern voice-cloning stack. Detectors trained on it do not generalize to current threats.
We needed three things at once that no existing benchmark gave us:
Private labels. A vendor cannot tune against a test set it cannot read.
A modern attack distribution. The synthetic side has to reflect what attackers are actually shipping in 2025.
Realistic format diversity. Production audio arrives as mp3, m4a, webm — not just 16 kHz wav.
A neutral benchmark for audio deepfake detection
Resemble AI and Aurigin AI both clear 96% accuracy on a fixed, format-rich, private-label test set. Their error profiles are different — and the right choice for your deployment depends on whether catching fakes or avoiding false alarms is more critical to your use case.
What is in the data
Real audio: VCTK (110 UK English speakers), LJSpeech (single voice), LibriTTS-360 (904 speakers).
Synthetic audio: ~25 modern TTS systems including ElevenLabs, F5-TTS, and Chatterbox. Every clip is round-trip verified through OpenAI Whisper to ensure the TTS system actually synthesized the intended utterance.
Six file formats: mp3, wav, flac, ogg, m4a, webm. Performance is reported per format — detectors leaning on codec artifacts reveal themselves in the breakdown.
Class balance is 50/50 real vs. fake across 4,524 audio clips. The gold-standard labels stay private to keep the benchmark honest.
We deliberately do not report Equal Error Rate. EER assumes you can pick the operating threshold; in production you ship at the threshold the vendor ships with.
Results
Repo: https://github.com/podonos/audio-dfd-benchmark
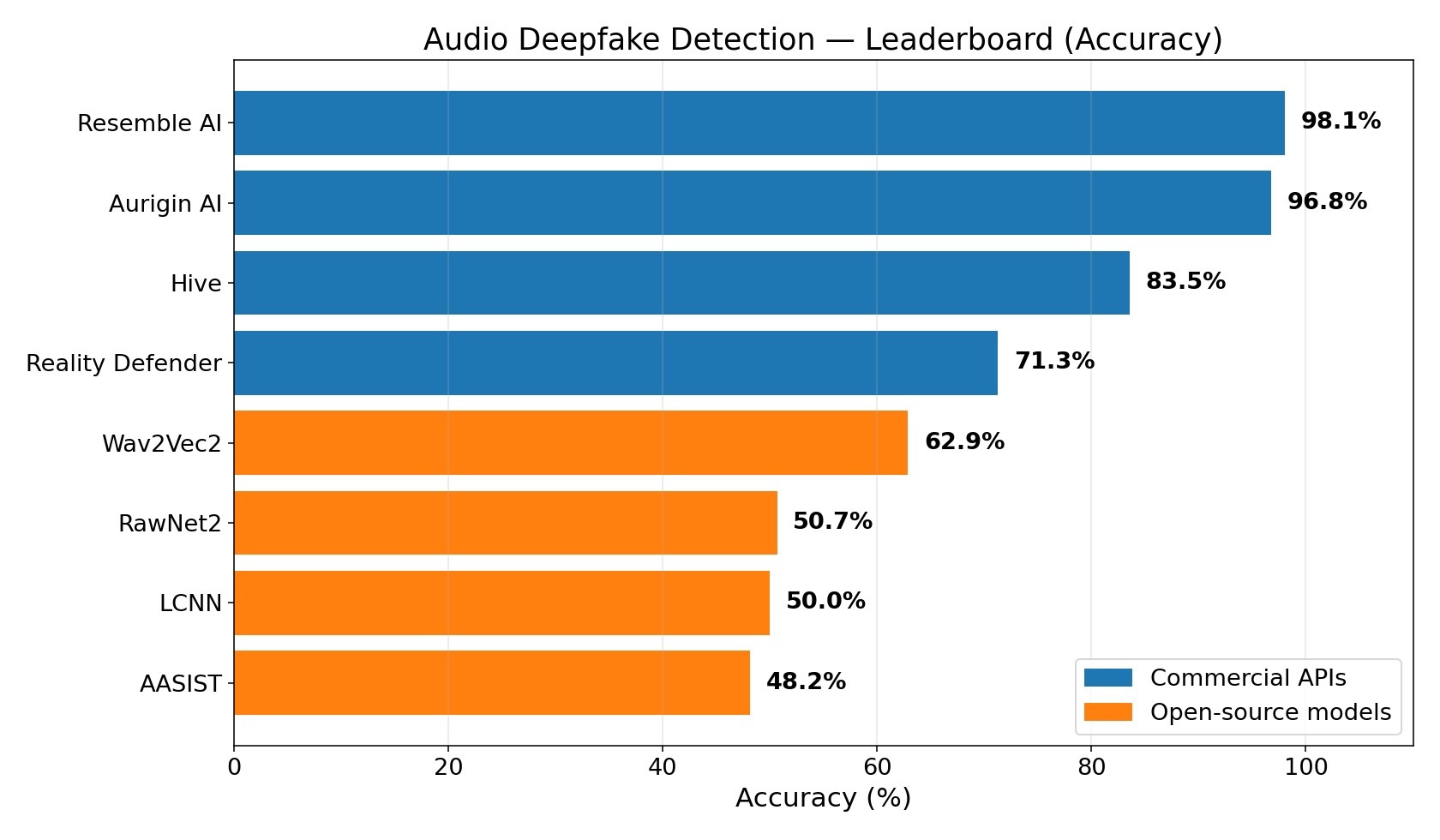
Three observations
Resemble AI and Aurigin AI both lead the field — they are similarly strong, with different shapes.
Resemble AI lands at 98.05% accuracy with a 1.4% false negative rate (it almost never misses a fake) and a 2.5% false positive rate. Aurigin AI lands at 96.75% accuracy with a 1.5% false positive rate (it almost never wrongly flags real audio) and a 5.0% false negative rate. Both are production-grade, both clear F1 0.96+. The gap between them and the rest of the field is enormous: more than 13 percentage points to #3.
The open-source baselines collapse.
All four of Wav2Vec2, RawNet2, LCNN, and AASIST were trained on ASVspoof 2019 LA, and all four score between 48% and 63% on this dataset — barely better than random. LCNN simply predicts "fake" for every input. The pattern is not really about open-source vs. commercial; it is about the obsolescence of ASVspoof as a training distribution.
Reality Defender's profile is unusual.
71.3% accuracy, 53.7% false-positive rate (it flags more than half of real audio as fake), 17.2% rejection rate (clips under 1.5 seconds are not evaluated), and a real-time factor of 1.52 (slower than real-time).
Which error matters more for you?
The most useful chart for buyers is the trade-off between false positives and false negatives. The two leaders sit at opposite corners of it.
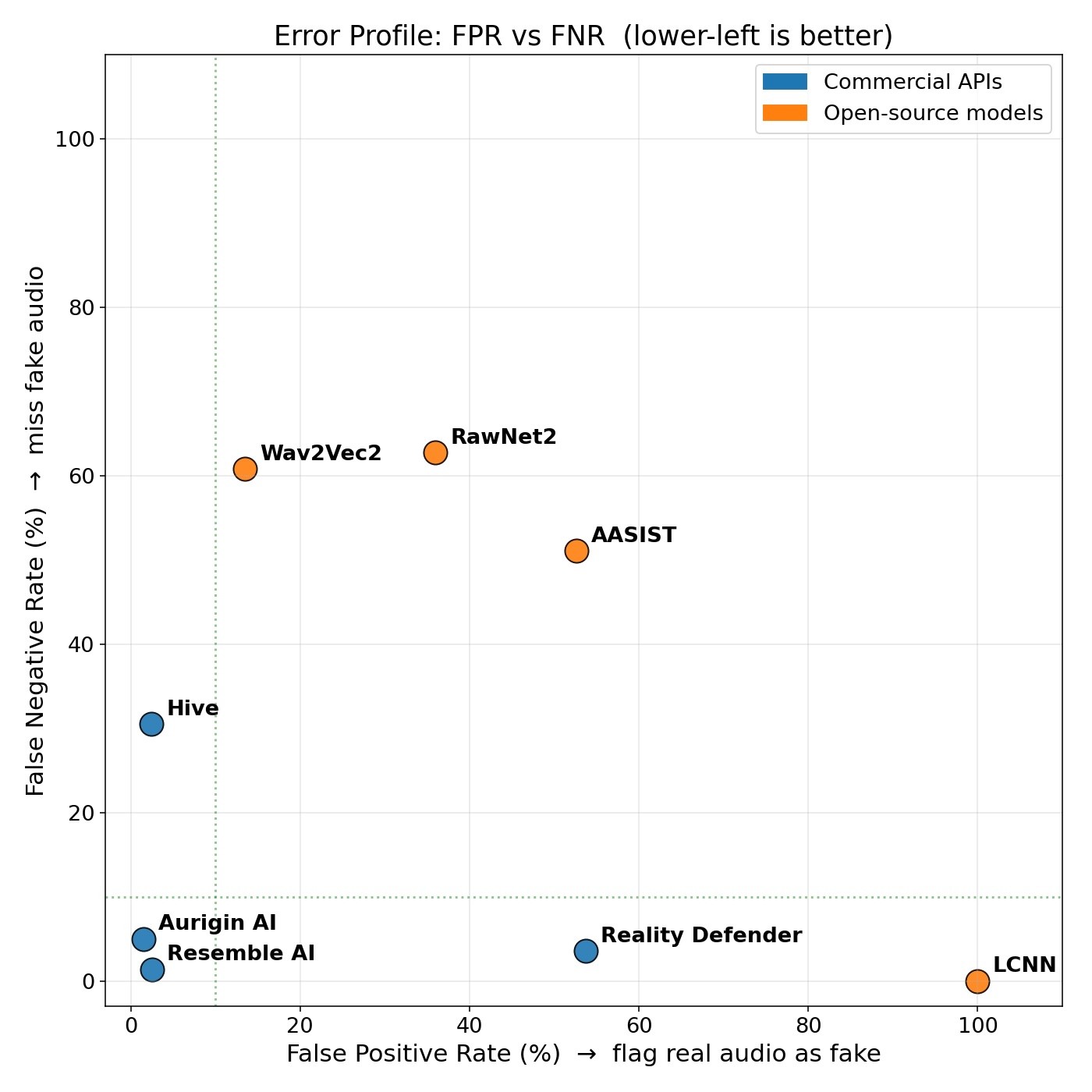
Resemble AI and Aurigin AI are similarly good. The choice between them is a choice between error profiles, not between products:
Voice-fraud screening, KYC, content provenance: missing a fake is the most expensive error. Lower FNR wins Resemble AI.
Content moderation at scale, automated takedowns, journalism verification: false-flagging real users is the most expensive error. Lower FPR wins Aurigin AI.
Most teams should evaluate both on a representative slice of their own traffic. Beyond raw accuracy, check whether each vendor can customize model sensitivity to match your error-tolerance profile.
Latency matters too
Streaming and real-time use cases need a real-time factor below 1.0. Reality Defender at 1.52 fails this bar regardless of accuracy. The open-source models are fast (RTF 0.006–0.14) but, as the leaderboard shows, do not work on the data. Resemble AI and Aurigin AI both land near RTF 0.33–0.40, well within real-time budgets.
Caveats
English-only. Non-English voice cloning is real and we do not have a read on it yet.
Snapshot in time. The TTS landscape is moving quickly. We plan to refresh the synthetic side regularly.
We hold the labels. Unavoidable for the design to work; every other component (data construction, request schemas, scoring code) is inspectable.
Links
Related work:
Commercial APIs evaluated: Aurigin AI, Resemble AI, Hive, Reality Defender.
Open-source baselines: AASIST, RawNet2, Wav2Vec2, LCNN-LFCC.
To submit a detector, drop a predictions.csv in the format documented in the repo. We are happy to score it against the held-out labels and publish the result.
Other readings

Natural ≠ Preferred: What Our TTS Rankings Revealed About How Humans Actually Judge AI Voices
Quickly uncover deep insights into your voice AI's strengths and drive faster development, smarter marketing, and flawless delivery.
May 28, 2026
|
7 min read

Announcing the Selected Teams for the Podonos Research Support Program
Quickly uncover deep insights into your voice AI's strengths and drive faster development, smarter marketing, and flawless delivery.
January 26, 2026
|
2 min read

Benchmarking Chatterbox Turbo: How Resemble AI Evaluated Open-Source Voice AI with Podonos
Quickly uncover deep insights into your voice AI's strengths and drive faster development, smarter marketing, and flawless delivery.
December 16, 2025
|
5 min read

Introducing Podonos Flash
Quickly uncover deep insights into your voice AI's strengths and drive faster development, smarter marketing, and flawless delivery.
December 3, 2025
|
4 min read

Podonos just raised $2.4M in pre-seed funding
Quickly uncover deep insights into your voice AI's strengths and drive faster development, smarter marketing, and flawless delivery.
September 10, 2025
|
3 min read

Product Update: Podonos Wizard launch
Quickly uncover deep insights into your voice AI's strengths and drive faster development, smarter marketing, and flawless delivery.
July 28, 2025
|
2 min read

Why Post-Refining Matters in Voice AI: Making Sense of Raw Evaluation Data
Quickly uncover deep insights into your voice AI's strengths and drive faster development, smarter marketing, and flawless delivery.
July 21, 2025
|
2 min read

Prescreening Human Evaluators: The First Step Toward Reliable Voice AI Evaluation
Quickly uncover deep insights into your voice AI's strengths and drive faster development, smarter marketing, and flawless delivery.
July 7, 2025
|
3 min read

Beyond English: Expanding TTS Evaluation into Multi-languages
Quickly uncover deep insights into your voice AI's strengths and drive faster development, smarter marketing, and flawless delivery.
June 19, 2025
|
2 min read

Gemini 2.5 TTS vs. ElevenLabs: A Side-by-side Performance
Quickly uncover deep insights into your voice AI's strengths and drive faster development, smarter marketing, and flawless delivery.
June 12, 2025
|
2 min read