Intro
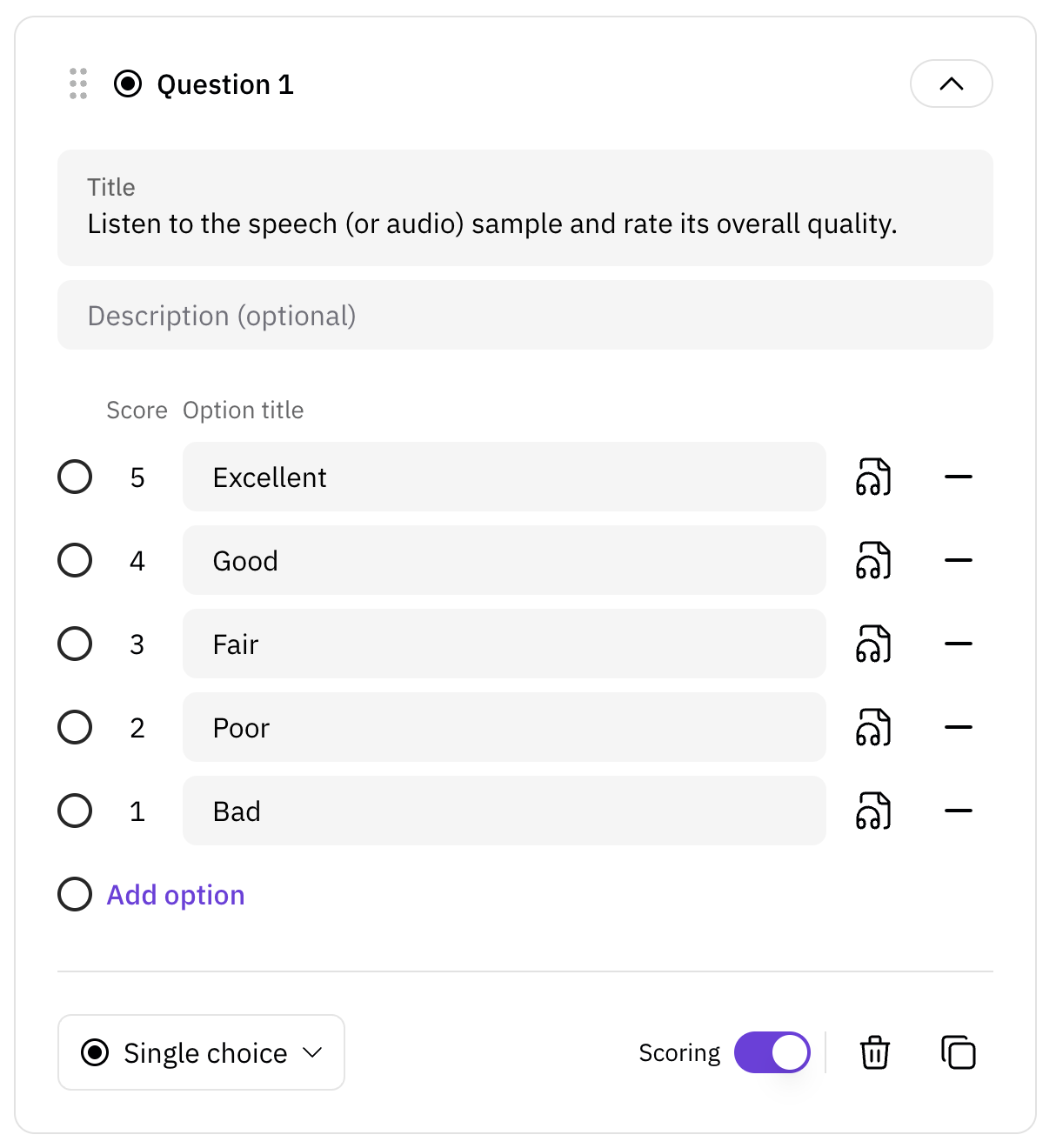
One of the popular questions in speech/audio evaluation is the quality of the generated output. It is not directly about naturalness or intelligbility. Quality is connected with many aspects including all those mentioned above. One of the widely used quality evaluation methods for speech/audio is mean opinion score (MOS). Its scale typically ranges from 1 (lowest quality) to 5 (highest quality like human) with 1 granularity (which is called five-point Likert Scale). Through podonos, you will evaluate the overall quality of your speech/audio in a fully managed service.