Overview
Annotation allows you to collect free-form text feedback from evaluators beyond simple ratings. This is useful for understanding the reasoning behind ratings or gathering specific feedback about audio quality issues.
There are two ways to enable annotations:
| Method | Description | Use Case |
|---|
use_annotation=True | Automatically adds annotation capability | Quick setup |
annotations array in JSON | Define custom annotation questions | Custom questions with specific targeting |
Method 1: Auto-Enable Annotation
The simplest way to collect feedback is to set use_annotation=True when creating an evaluator.
This also works with create_evaluator() and create_evaluator_from_template_json().
Method 2: Define Custom Annotation Questions in JSON
For more control, define annotation questions directly in your template JSON using the annotations array.
Single Stimulus Example
For single stimulus evaluations (NMOS, QMOS, etc.), use "ALL" or omit related_model:
Double Stimulus Example
For double stimulus evaluations (PREF, etc.), annotations are only available through the JSON annotations array (not use_annotation=True). You must specify "MODEL_A" or "MODEL_B" for each annotation:
The related_model parameter specifies which audio the annotation question applies to:
| Evaluation Type | Allowed Values | Description |
|---|
| Single stimulus (NMOS, QMOS, etc.) | "ALL" or omit | Feedback for the single audio |
| Double stimulus (PREF, etc.) | "MODEL_A" or "MODEL_B" | Feedback for specific audio |
For double stimulus evaluations, related_model is required and must be either "MODEL_A" or "MODEL_B". Using "ALL" will cause an error.
Important: Mutual Exclusivity
You cannot use use_annotation=True and the annotations array together. Choose one method:
Template JSON Schema
annotations Array
| Field | Type | Required | Description |
|---|
annotations | array | No | List of annotation questions |
annotations[].type | string | Yes | Must be "ANNOTATION" |
annotations[].question | string | Yes | Question text shown to evaluators |
annotations[].related_model | string | Conditional | "ALL", "MODEL_A", or "MODEL_B" |
annotations[].description | string | No | Additional guidance for evaluators |
Method Support
The use_annotation parameter is available in these methods:
| Method | use_annotation Support |
|---|
create_evaluator() | Yes |
create_evaluator_from_template() | Yes |
create_evaluator_from_template_json() | Yes |
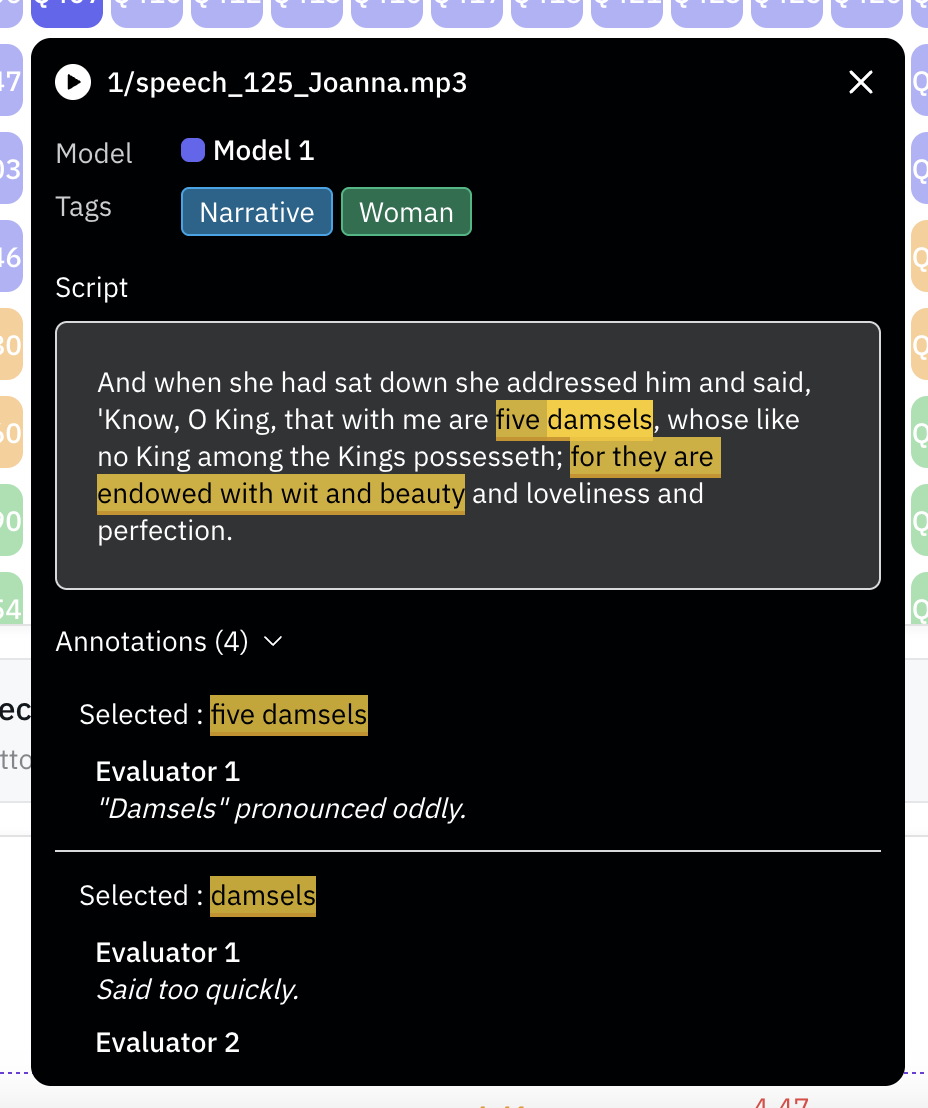
Viewing Annotation Results
Once the evaluation finishes, you can view the annotation results in the analysis tab:
 Click on a file to see the evaluator feedback:
Click on a file to see the evaluator feedback: