Jun 2026
Four new language locales
Below four language locales are live for evaluation with same panels, same metrics, native-speaker raters in-region.- Sinhala (Sri Lanka) —
si-lk - Arabic-Egypt —
ar-eg - Arabic-UAE —
ar-ae - Arabic-Saudi Arabia —
ar-sa
A public language reference
Every supported locale, on one page — with the expected panel turnaround time for each. Bookmark it before your next project.See the language list →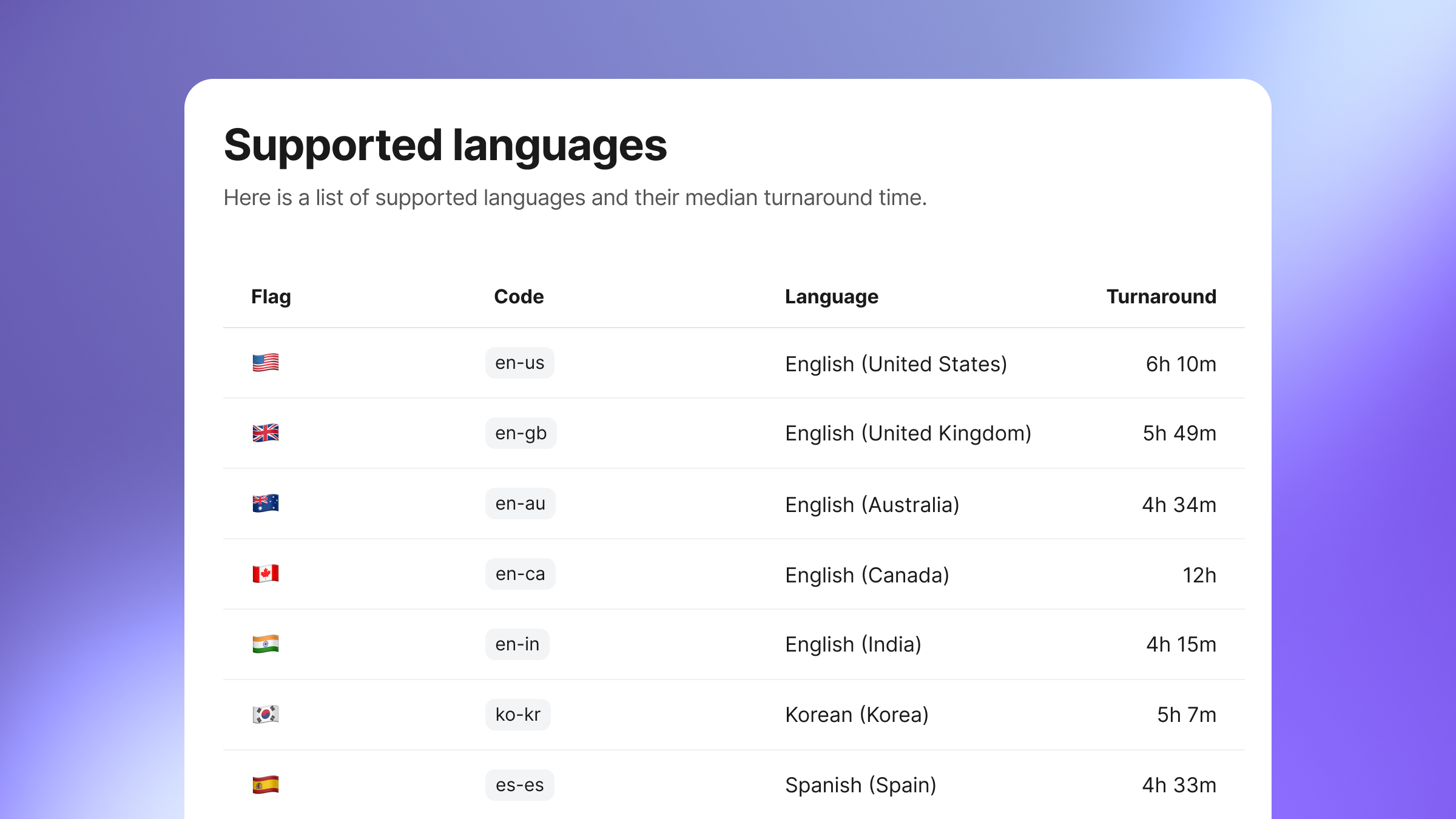
SOC 2 Type II — completed
Podonos completed its SOC 2 Type II audit. Controls covering security, availability, and confidentiality were tested across the audit window and operated effectively.The report sits on the trust center.trust.podonos.com →
May 2026
Evaluation reliability — what runs behind every panel
Reliable scores don’t happen by accident.Behind every panel: vetted evaluator pools, per-session acoustic environment checks, embedded attention tests, audio shuffling and loudness normalization, and post-session cohort scoring with automatic backfill of underperformers.The full pipeline, what we screen for, what we reject, and how scores stay comparable run to run, language to language is documented.
Apr 2026
Expanded Language Coverage: South Asian Languages
We have added support for four major South Asian languages, broadening our reach for voice applications targeting the Indian subcontinent:- Hindi (India) —
hi-in - Tamil (India) —
ta-in - Kannada (India) —
kn-in - Malayalam (India) —
ml-in
Mar 2026
Mandatory Annotations for Specific Scores
You can now require evaluators to provide an annotation when they select certain score values.For example, if an evaluator rates a sample as “2”, they must explain why — ensuring you always get qualitative context behind quantitative ratings.- Define which score values trigger a mandatory annotation
- Annotation requirements are set per question, giving you precise control
- Works across single, double, and triple stimulus evaluation types

Automatic Annotation Translation
Understanding evaluator feedback just got easier — regardless of the language it was written in.Previously, annotations were only available in the language the evaluator used. Now, annotations are automatically translated into English in the Report views. Run evaluations with native-language evaluators worldwide and read every annotation without extra steps.Improved Audio Download Reliability
We resolved an issue that caused “Failed to fetch” errors when downloading audio files from evaluations. This was caused by a cross-origin configuration issue affecting certain file access patterns.Audio file downloads now work reliably across all evaluation types and browser configurations. No action is needed on your end.
Feb 2026
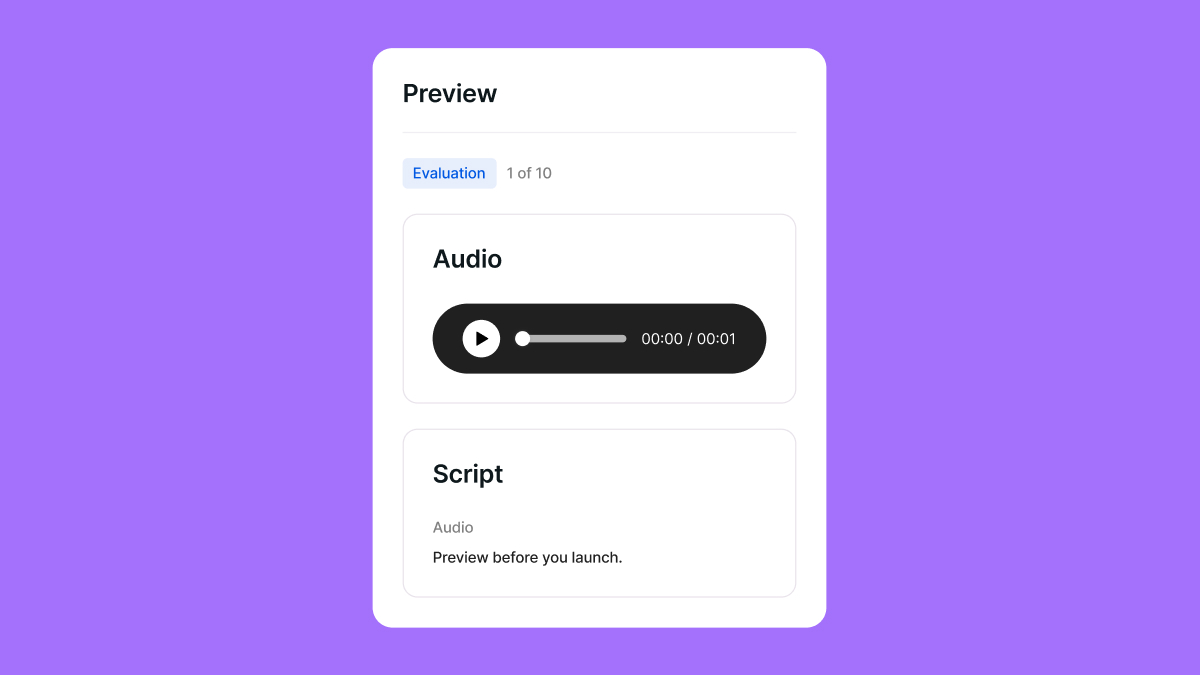
Evaluator Preview
You can now preview what evaluators will see before launching an evaluation.This preview shows:- Instructions and questions as they appear to evaluators
- The actual layout evaluators interact with
Richer Annotation Instructions
Annotation just became more expressive. You can now add an annotation type directly to each question and include a detailed description explaining exactly what should be annotated.For example, you can explicitly ask evaluators to annotate:- Incorrect pronunciation
- Background noise
- Awkward or unnatural pronunciation segments

Comparative Similarity SDK Workflow
Creating comparative similarity evaluations via SDK is now simpler and more consistent.Previously, evaluations had to be partially created in the SDK and then manually completed in the workspace. Now, you can use atemplate.json directly in the SDK to create a complete evaluation end-to-end without manual workspace setup, making evaluation creation more reproducible and automation-friendly.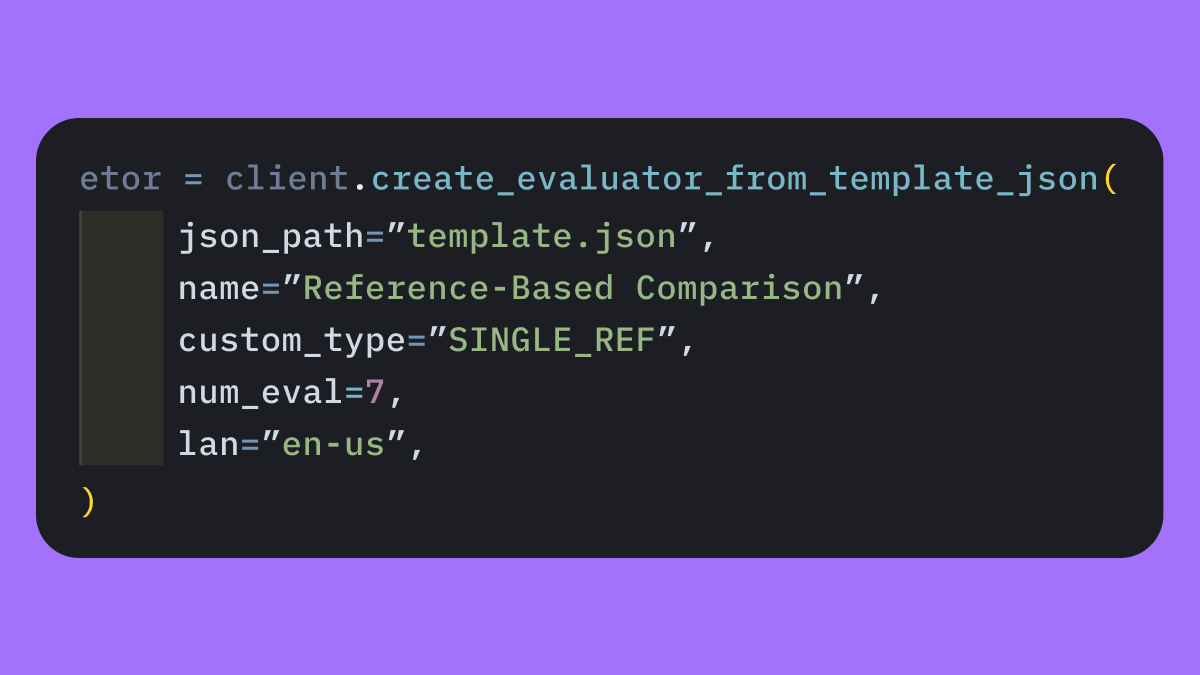
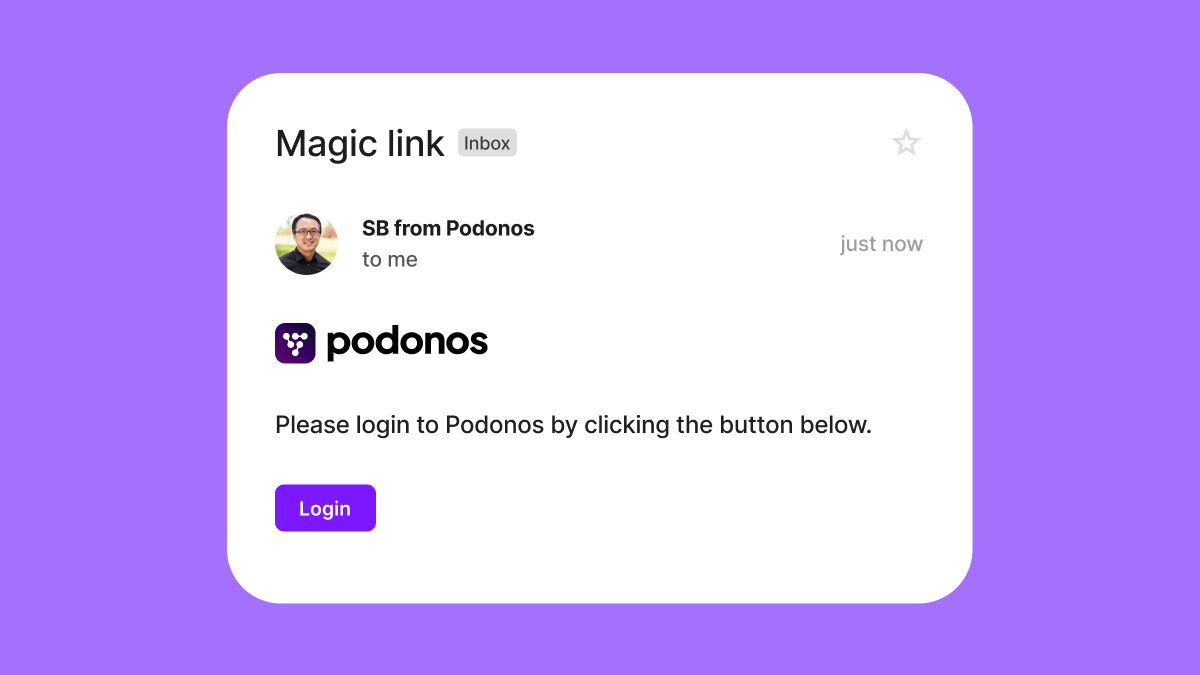
Passwordless Login
As an additional security step, we have fully transitioned to magic URL login:- No more passwords to remember or manage
- All existing passwords have been securely deleted from our system
SOC 2 Type I Certification
Podonos has passed SOC 2 Type I and has successfully completed external penetration testing. We are currently in the observation period for Type II.You can always find our latest security updates at our Trust Center.
Jan 2026
Slack Notifications for Evaluation Status
Stay updated without checking your inbox.In addition to email notifications, Podonos now supports Slack integration for evaluation status updates. You can receive notifications when an evaluation starts and when it finishes, directly in Slack.- Slack alerts for evaluation start and completion
- Ideal for team visibility and real-time monitoring
- Easy to integrate into existing workflows

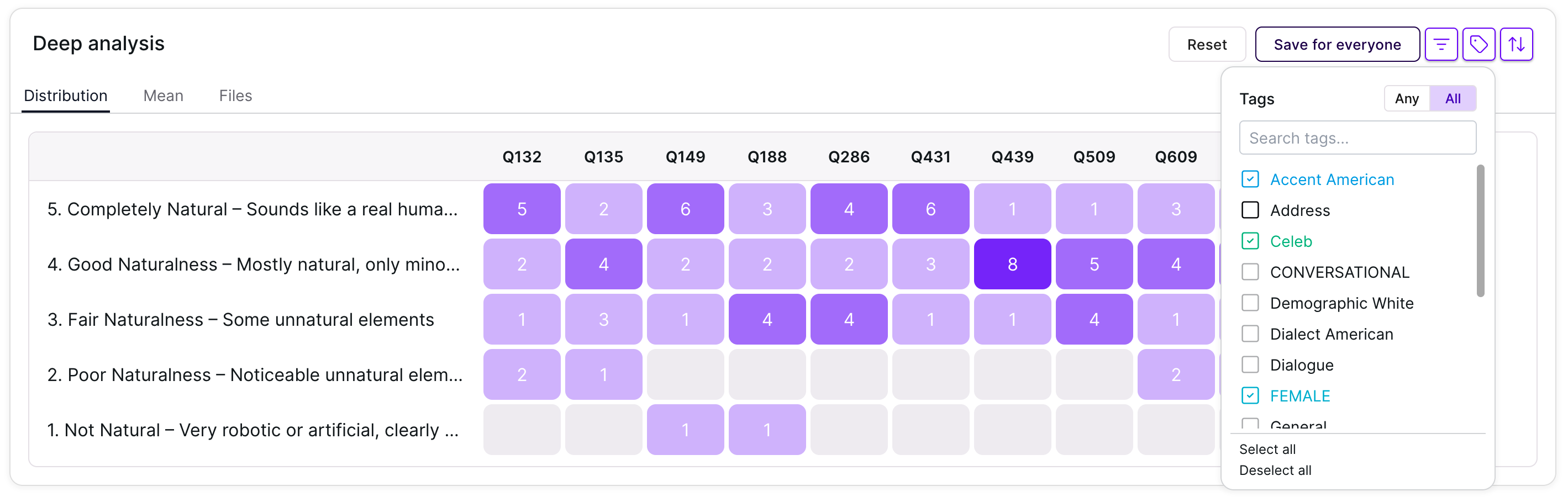
Advanced Tag Filtering in Deep Analysis
We added an Any/All toggle to the tag filter within the Deep Analysis section of reports.This feature provides flexible filtering logic:- Any: Matches results containing at least one of the selected tags.
- All: Matches results containing every selected tag.
Dec 2025
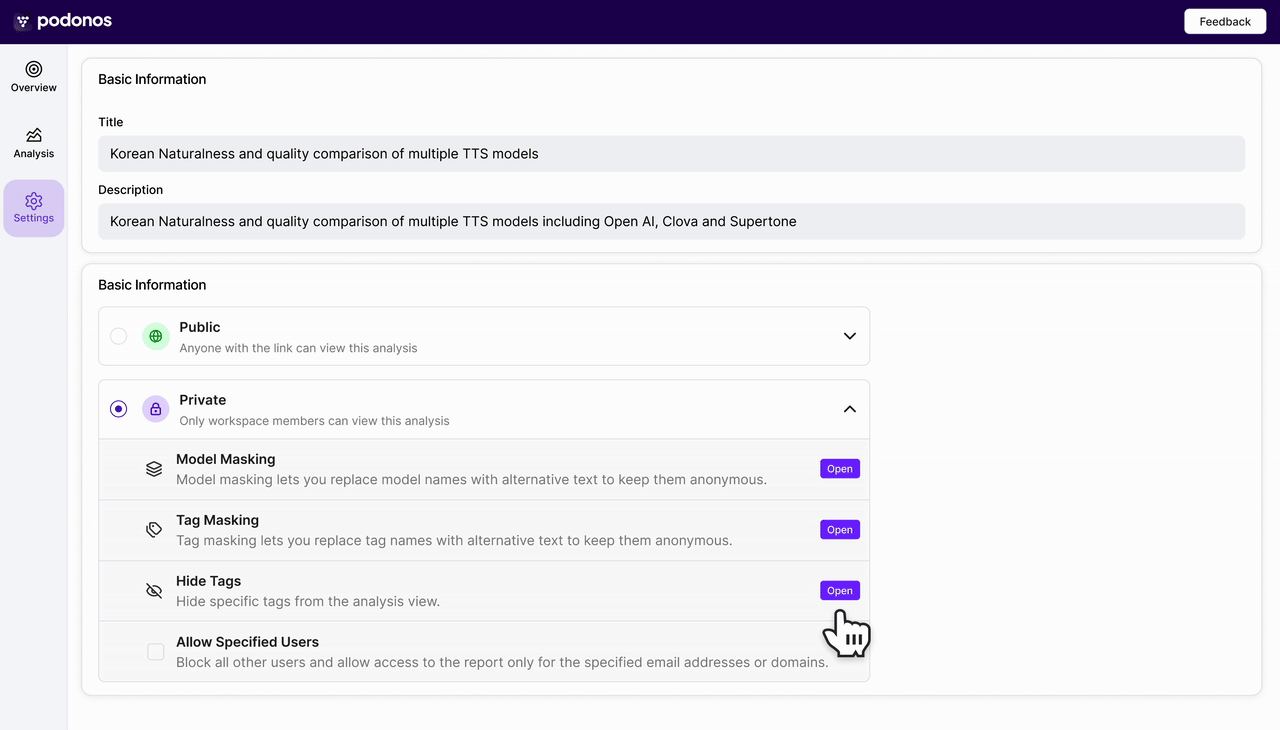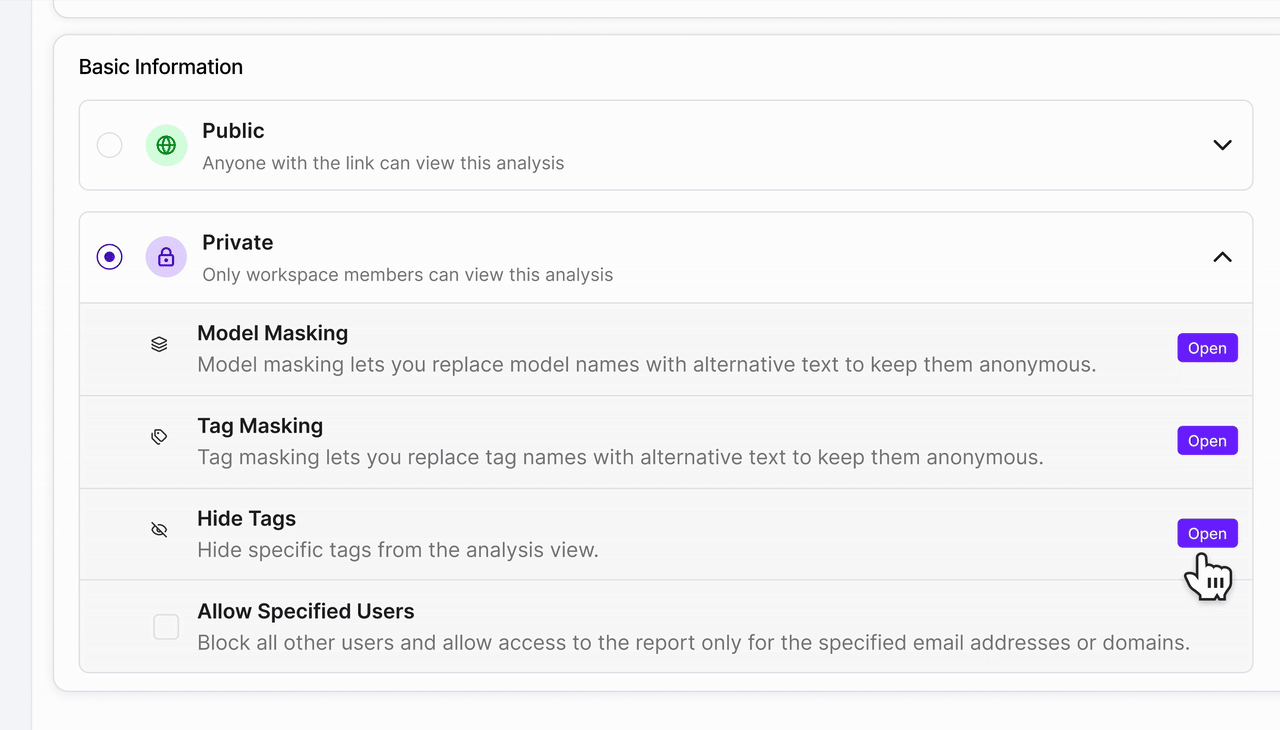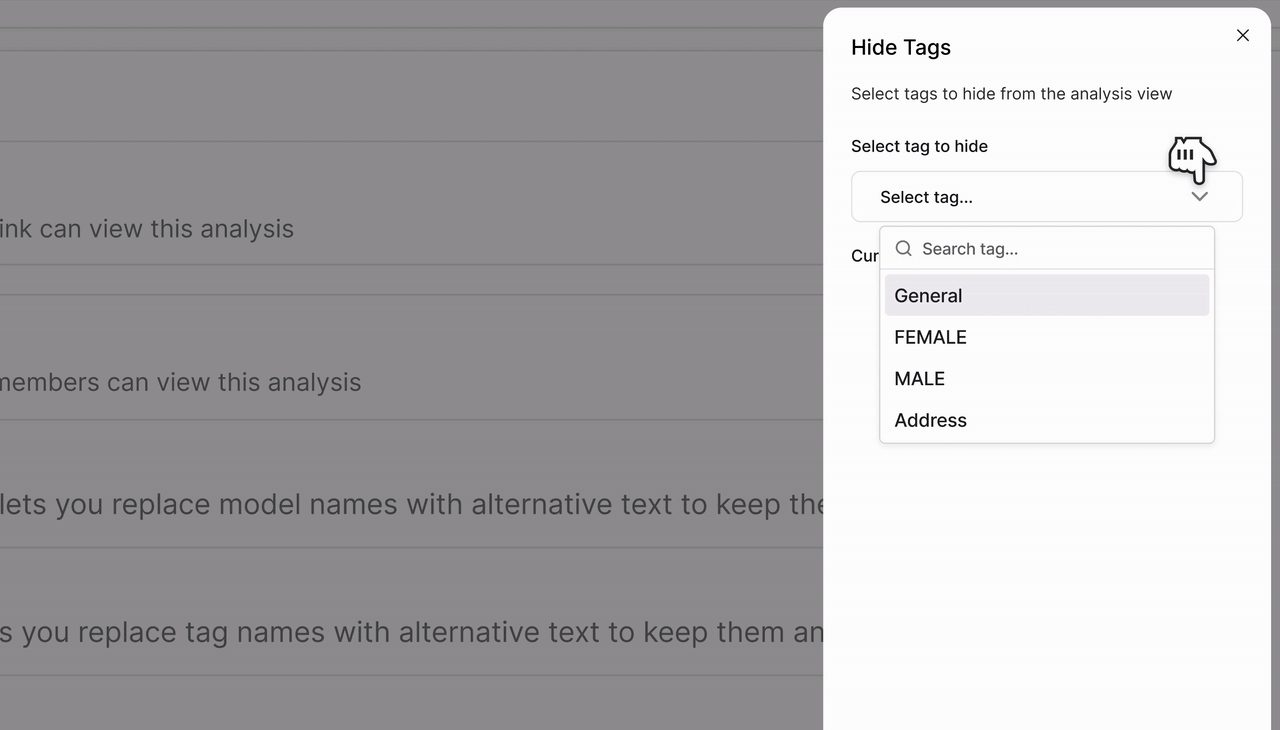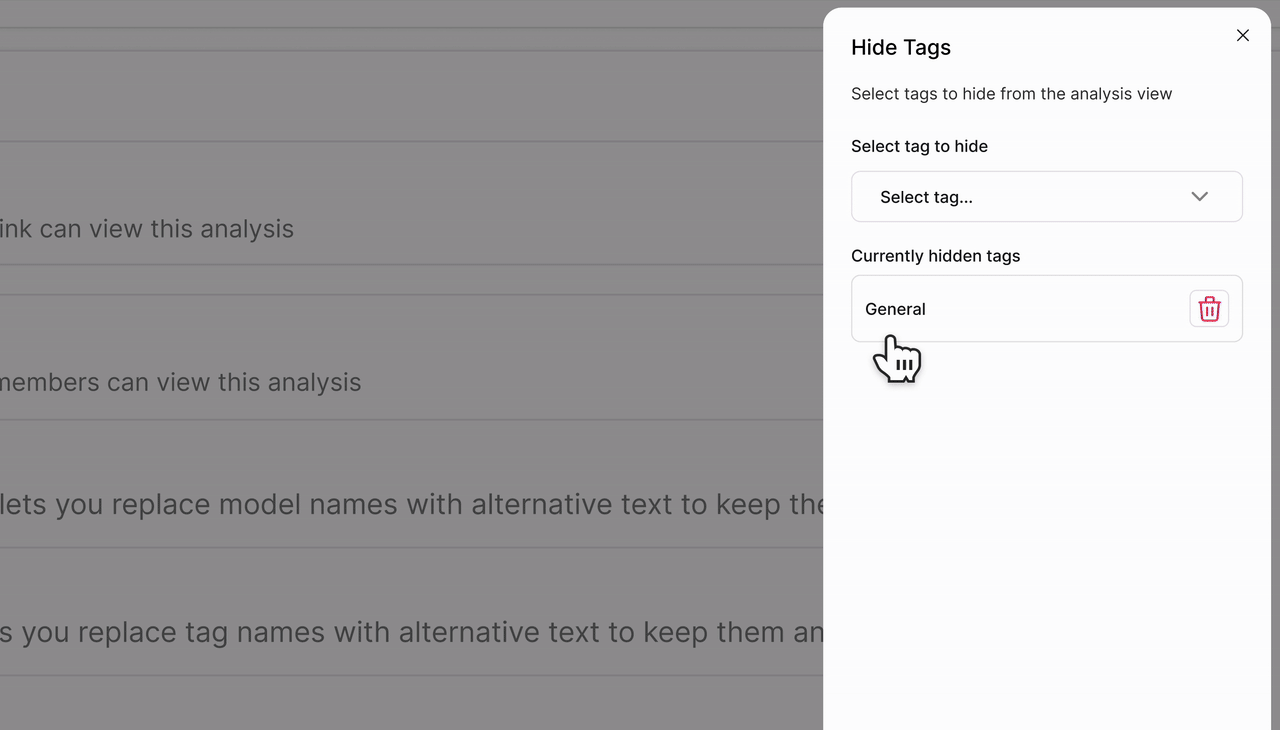
Smarter Tag Control with Invisible Tags
Keep reports clean without losing important context.You can now hide specific tags from your report pages while keeping them intact in the evaluation setup. This makes it easier to share reports externally without exposing internal or experimental metadata.- Hide selected tag(s) from the report UI
- Tags remain available internally for filtering and organization
- Configure hidden tags in Report Settings → Hide tags
Auto Translation During Evaluation Setup
Create multilingual evaluations with less effort.When creating an evaluation, you first select a target language. Any instruction or question you enter, regardless of the original language, can be automatically translated into the target language with a single click.- Target language defined at evaluation creation
- One-click translation for instructions and questions
- Reduces friction when setting up global evaluations
Filter by demographic
We have added a feature that allows you to filter evaluation results by combining tags with evaluator demographics, such as region, age, and gender. You can create up to 10 different combinations to compare results at a glance. Check it out in the Sample Report!
Status Page
We have released our Status Page, enabling real-time monitoring of system status. This includes service uptime, server availability, and API health, providing greater transparency and reliability for your operations.
Trust Center
We have officially initiated our SOC 2 Type II audit. Security and data protection are core foundations at Podonos, and this audit represents another step toward meeting the highest industry standards. We are committed to transparent operations and maintaining a secure environment for all customer data.To learn more about our security practices or stay updated on our audit progress, please visit our Trust Center.
Save and Revert Buttons
You can now manually Save your progress or Revert changes while creating an evaluation. These controls provide greater flexibility and safety when configuring your evaluation tasks.Report settings updates
You no longer need to wait for an evaluation to complete to access report settings. You can now modify report configurations—including title, description, sharing setup, and short URL—anytime, even while the evaluation is in progress.Quick Access to Previous Recipients
In Report Sharing settings, you can now quickly access and add emails or domains used in previous evaluations. This list history feature streamlines the process of sharing reports with your frequent stakeholders.Nov 2025
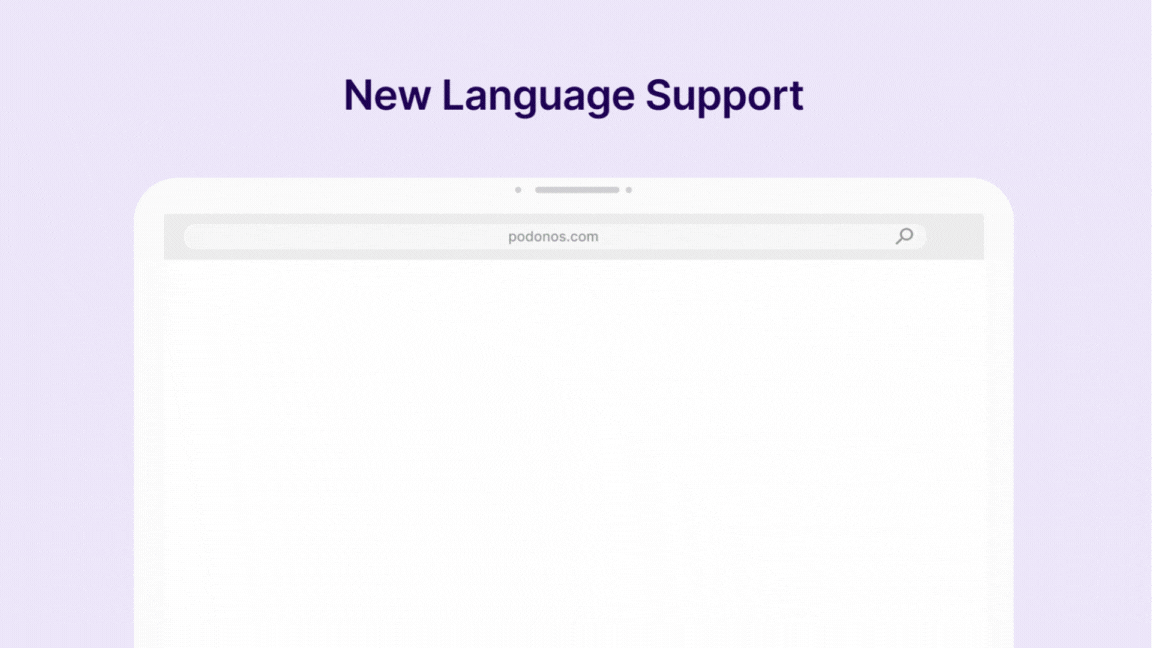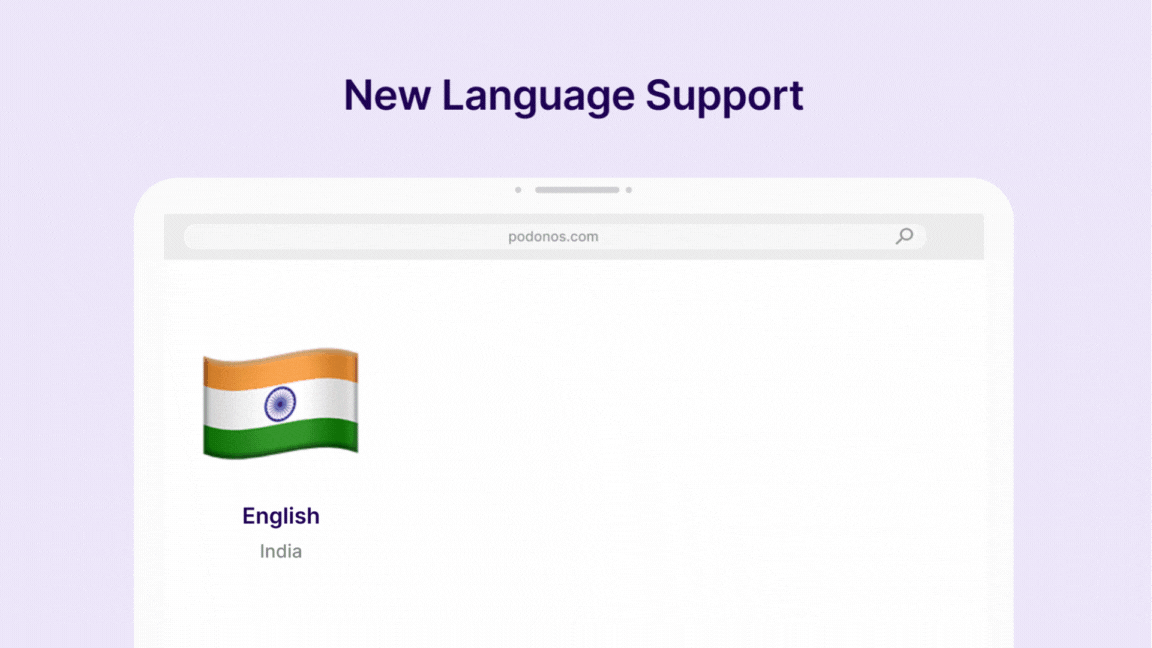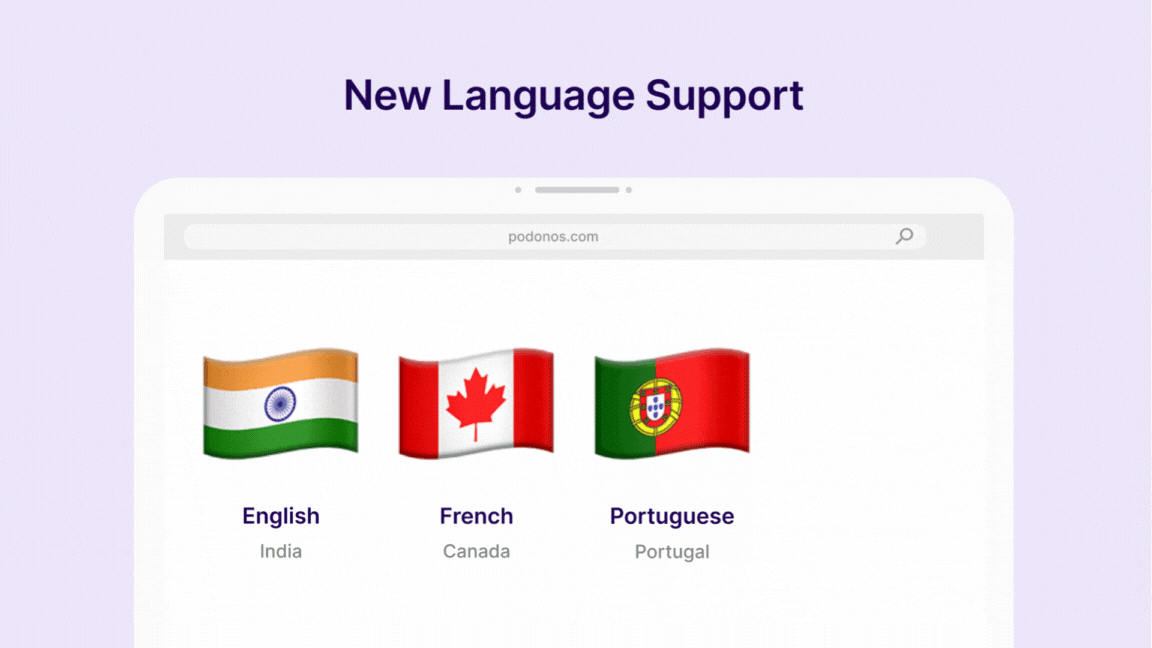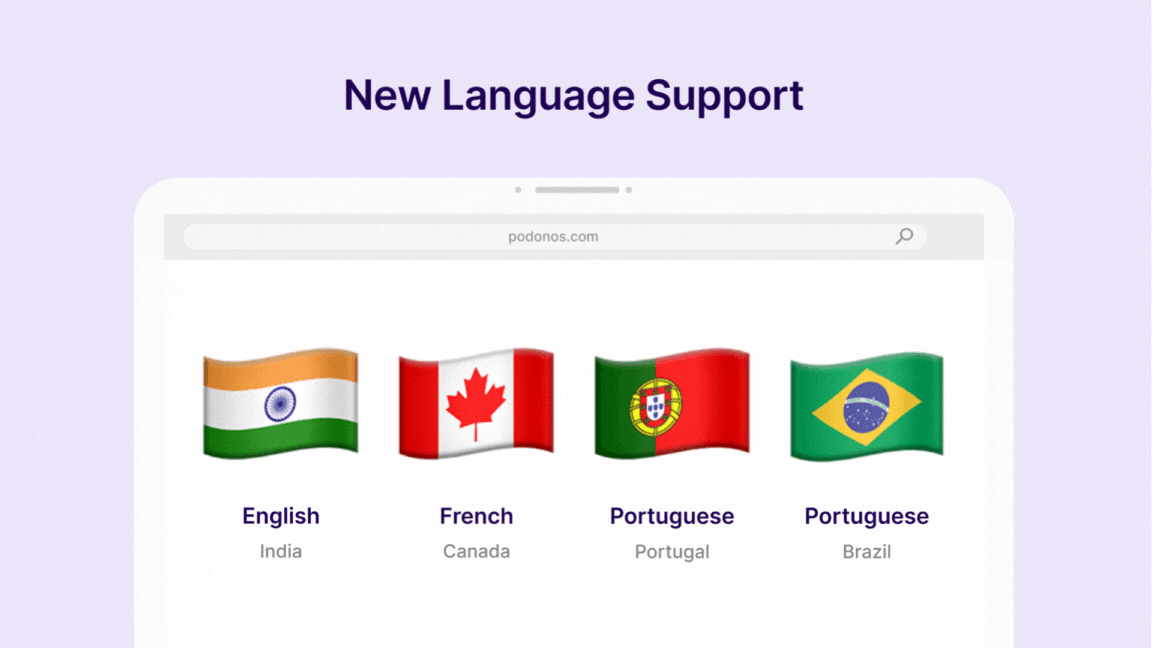
Expanded Language Coverage
We have expanded our language support to include key regional dialects:- Indian English
- Canadian French
- Brazilian Portuguese and Portugal Portuguese
Podonos Flash (Alpha): The World’s First Voice Evaluation API
Introducing Podonos Flash, the first-ever API designed for real-time voice evaluation.While human evaluation offers superior accuracy, it can be resource-intensive. Podonos Flash bridges this gap by instantly assessing naturalness and noise quality with human-like precision, enabling large-scale performance monitoring and optimization.Currently in Alpha Testing. We are refining the system for a full official launch in January 2026.During this Alpha phase, we are offering limited early access to select partners. To request access, please contact us at hello@podonos.com.Learn more
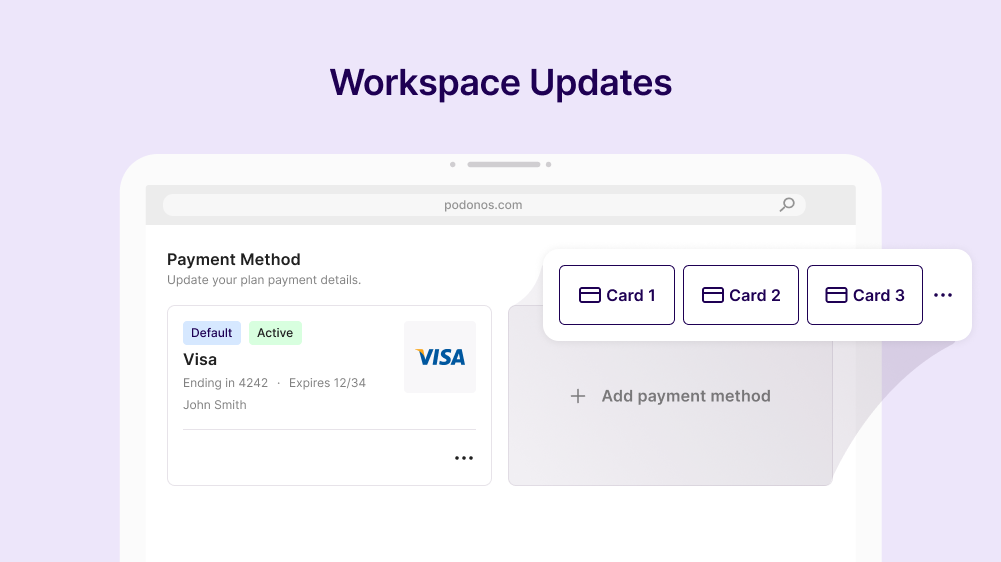
Workspace Enhancements
We have introduced key administrative and billing improvements to the Workspace:- Admin Role Transfer: Seamlessly transfer administrative privileges within your organization.
- Multi-Payment Method Support: Register and manage multiple payment methods for flexible billing operations.
Oct 2025
New: Transcription Services
We have launched High-Accuracy Transcription Services, essential for benchmarking speech-to-text models and generating high-quality training datasets.Our service supports 12 major languages, including English, Spanish, French, Japanese, Korean, and German, ensuring reliable ground truth data for your AI models.U.S. Address Speech Dataset
Accurate address processing is critical for voice AI systems yet remains a common failure point. To address this, we have curated a Verified U.S. Address Speech Dataset to help benchmark and improve your model’s performance on complex address formats.Contact us to access this high-value dataset.
Secure Report Sharing
Enhance team collaboration with Secure Report Sharing. You can now securely distribute evaluation reports to internal teammates and external partners, ensuring stakeholders have controlled access to performance insights.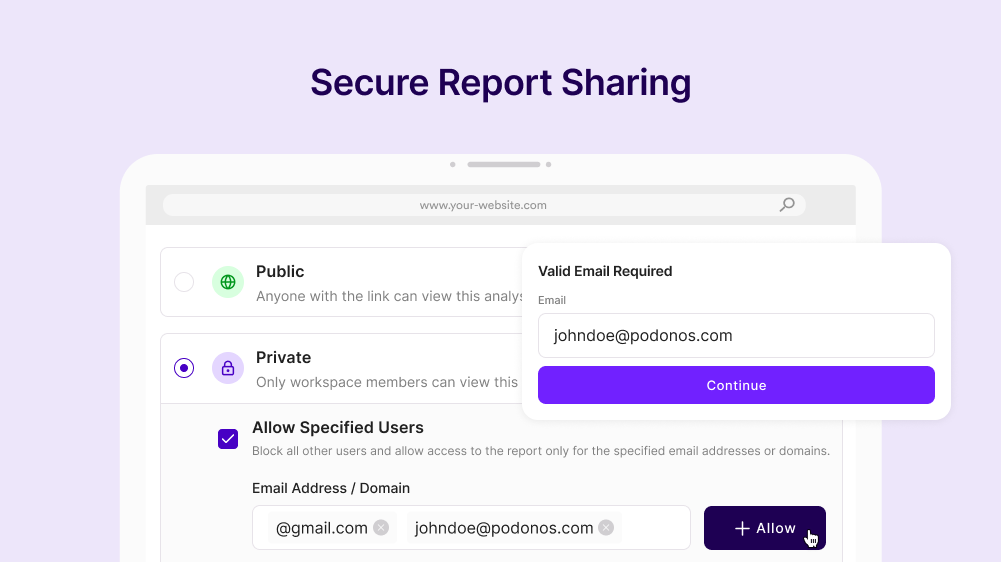
Jul 2025
Recommended Templates
Streamline your evaluation workflow with Recommended Templates.Available via both SDK and Web, these pre-configured templates allow you to rapidly set up evaluations aligned with standard industry goals, reducing configuration time and ensuring best practices.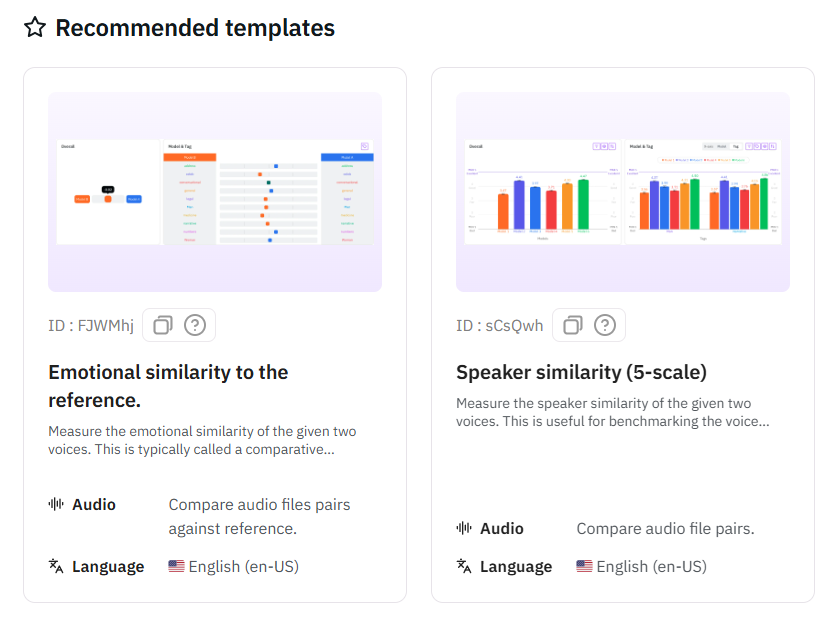
Jun 2025
Wizard
We’ve introduced a Wizard to streamline evaluation creation and accelerate your workflow.The API-based approach revolutionizes the evaluation process by enabling rapid evaluation creation through just a few clicks, eliminating the need for manual audio file generation and upload procedures. This streamlined method significantly reduces setup time while maintaining the same comprehensive evaluation capabilities.Currently, the API-based evaluation method supports single audio evaluation for naturalness and quality evaluation and double audio evaluation for voice similarity and preferences evaluation. We are actively working to extend API-based support to additional evaluation types and will be rolling out these capabilities in upcoming releases.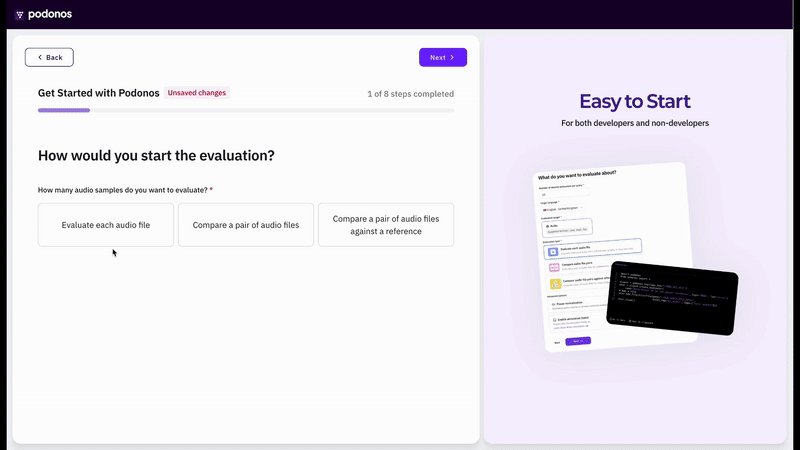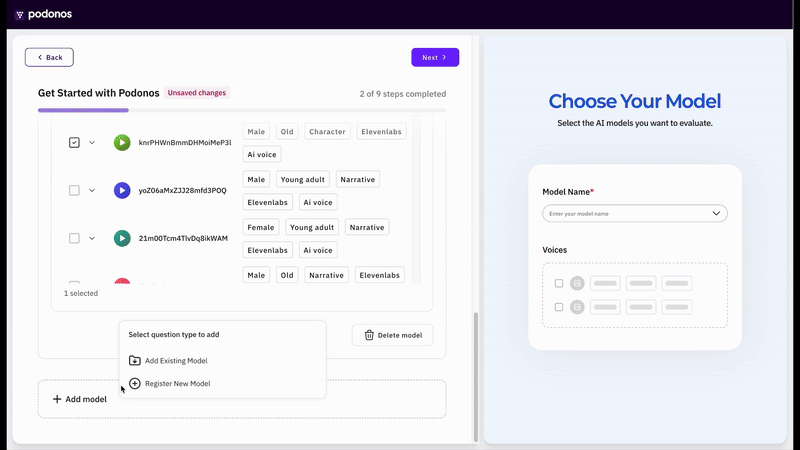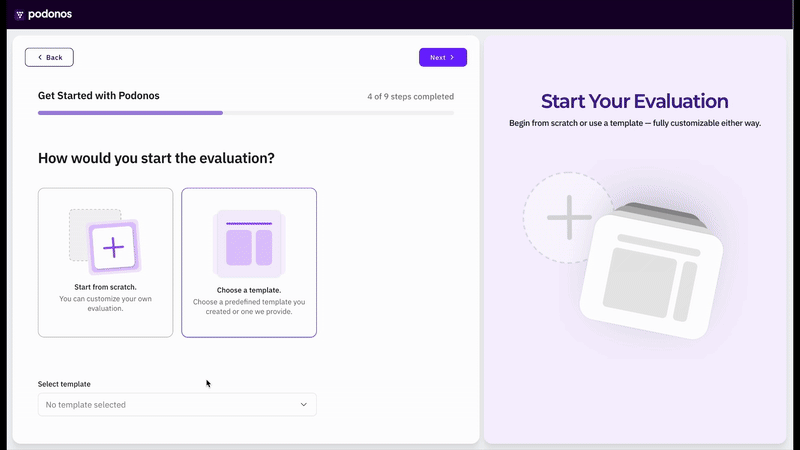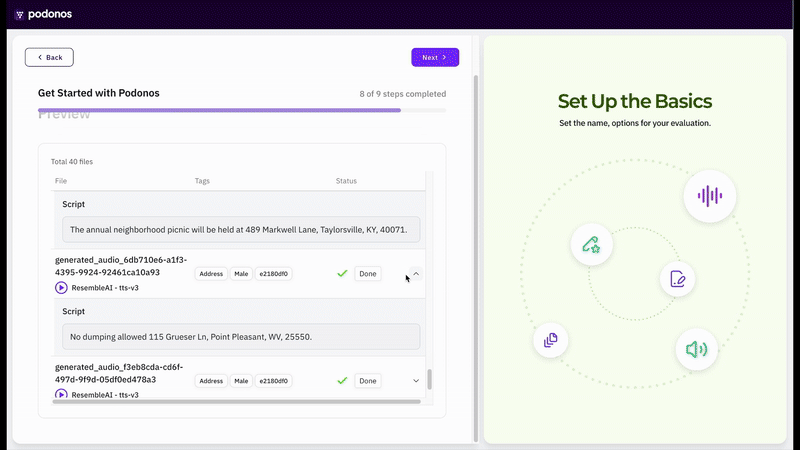
May 2025
Automatic Loudness Normalization
All audio inputs are automatically normalized to -21 LUFS before presentation to human evaluators, ensuring consistent and accurate evaluation results regardless of original audio levels.Apr 2025
Public Report Setup
You can now customize your report titles and descriptions at any time. When publishing reports publicly, you have full control over audio playability settings, model names, and tags.
Mar 2025
Data Collection (Beta)
Multi-language voice data collection from diverse global contributors to improve model performance. This service is currently available to selected early customers who are seeing significant improvements in model accuracy and speed.Feb 2025
Markdown Descriptions
Add comprehensive descriptions for your models and comparisons using markdown formatting, similar to README.md files on GitHub or Hugging Face. This enables rich documentation with formatted text, links, and structured content.
Report Download
Download complete analysis data in JSON format with three different organizational structures to suit your specific needs and workflows.
Voice Cloning Evaluation
Comprehensive voice similarity measurement for voice cloning applications. Our system supports three-way similarity analysis comparing a reference voice with two target outputs, enabling precise evaluation of voice cloning quality.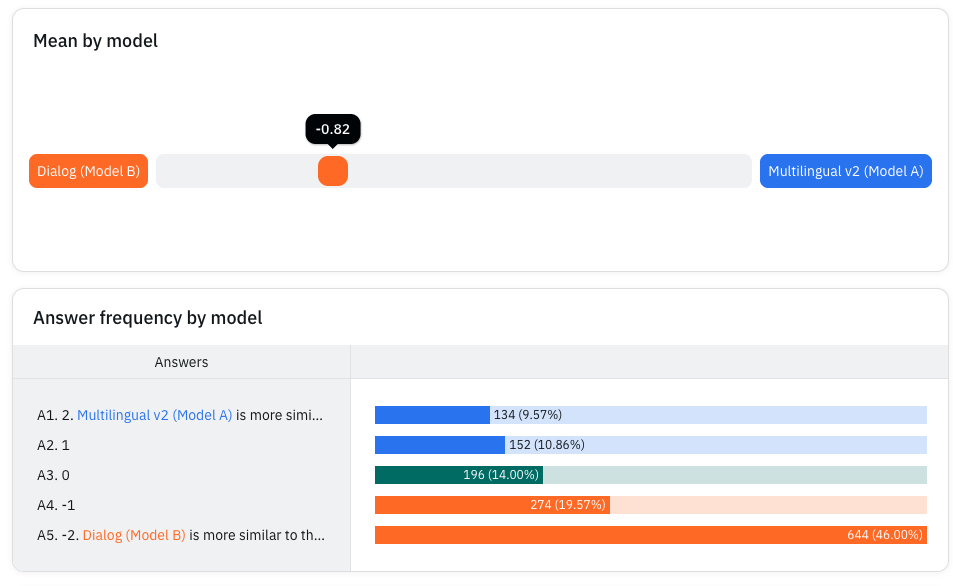
Model-related questions
In three-way similarity analysis, you can now ask specific questions related to each individual model. Through model-related questions, you can conduct separate evaluations for each model within the triple audio evaluation framework, providing the same level of detailed evaluation as single audio evaluations.This feature enables comprehensive analysis by allowing evaluators to focus on specific aspects of each model’s performance while maintaining the comparative context of the three-way evaluation structure.
Collaborate with team
Enable teamwork by sharing evaluations, feedback, and reports. Foster collaboration and ensure everyone stays aligned on goals and outcomes
Jan 2025
Web-based evaluation
You don’t need an SDK to create an evaluation any more.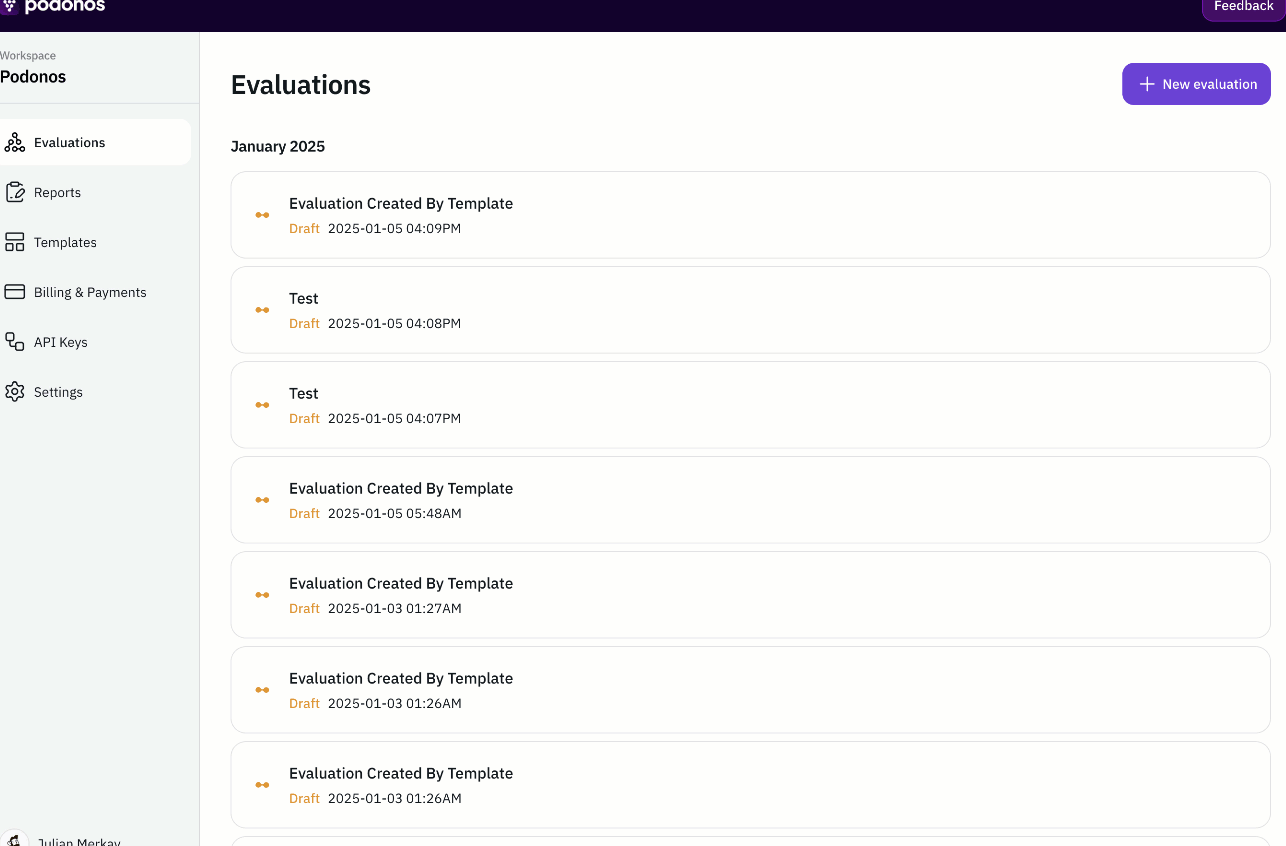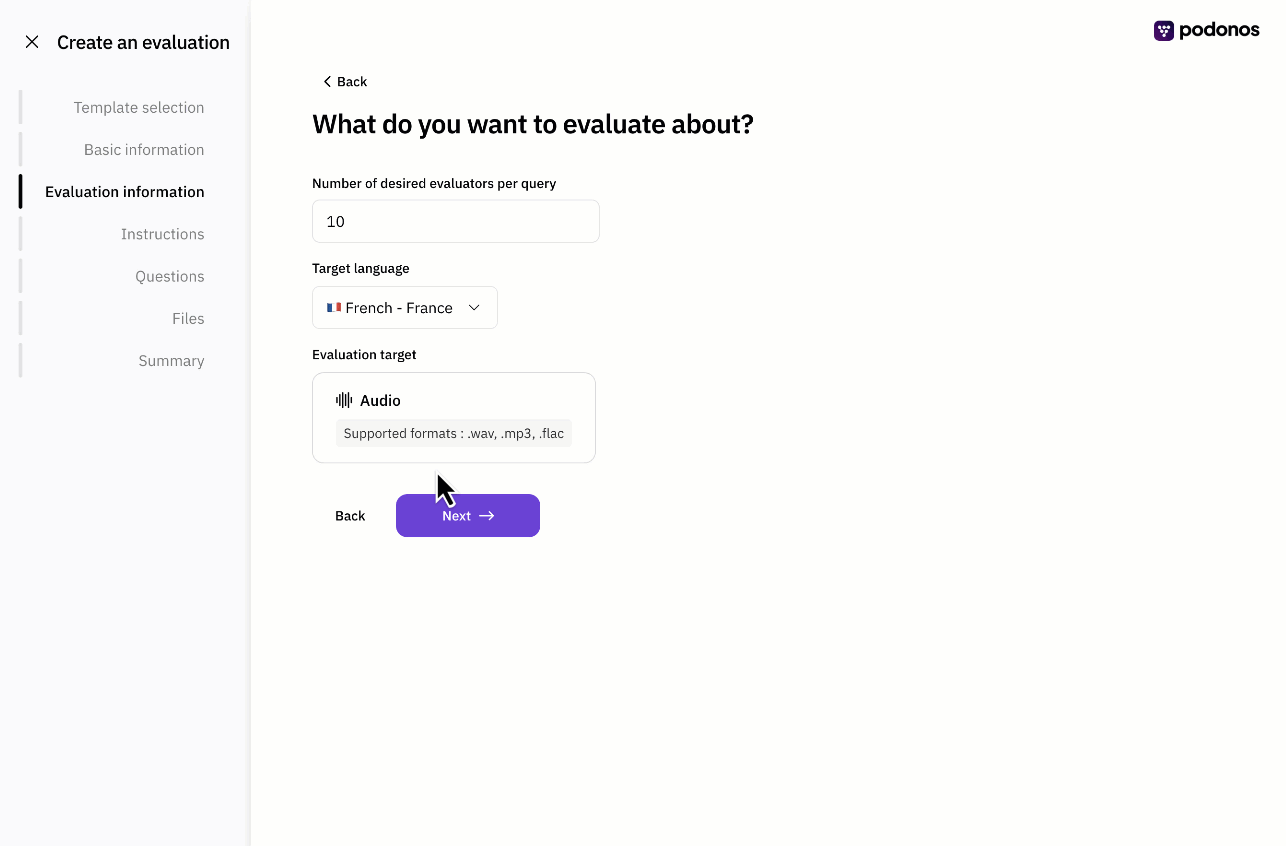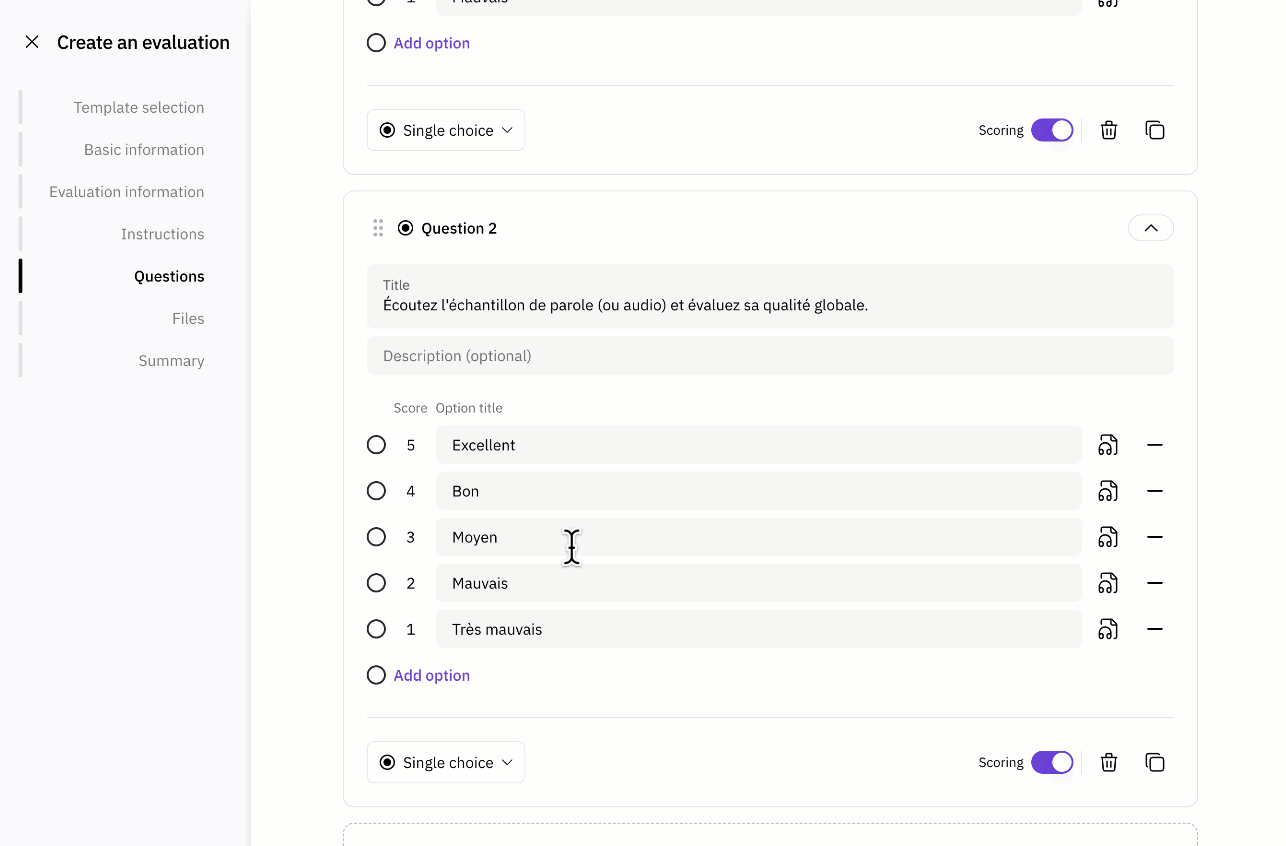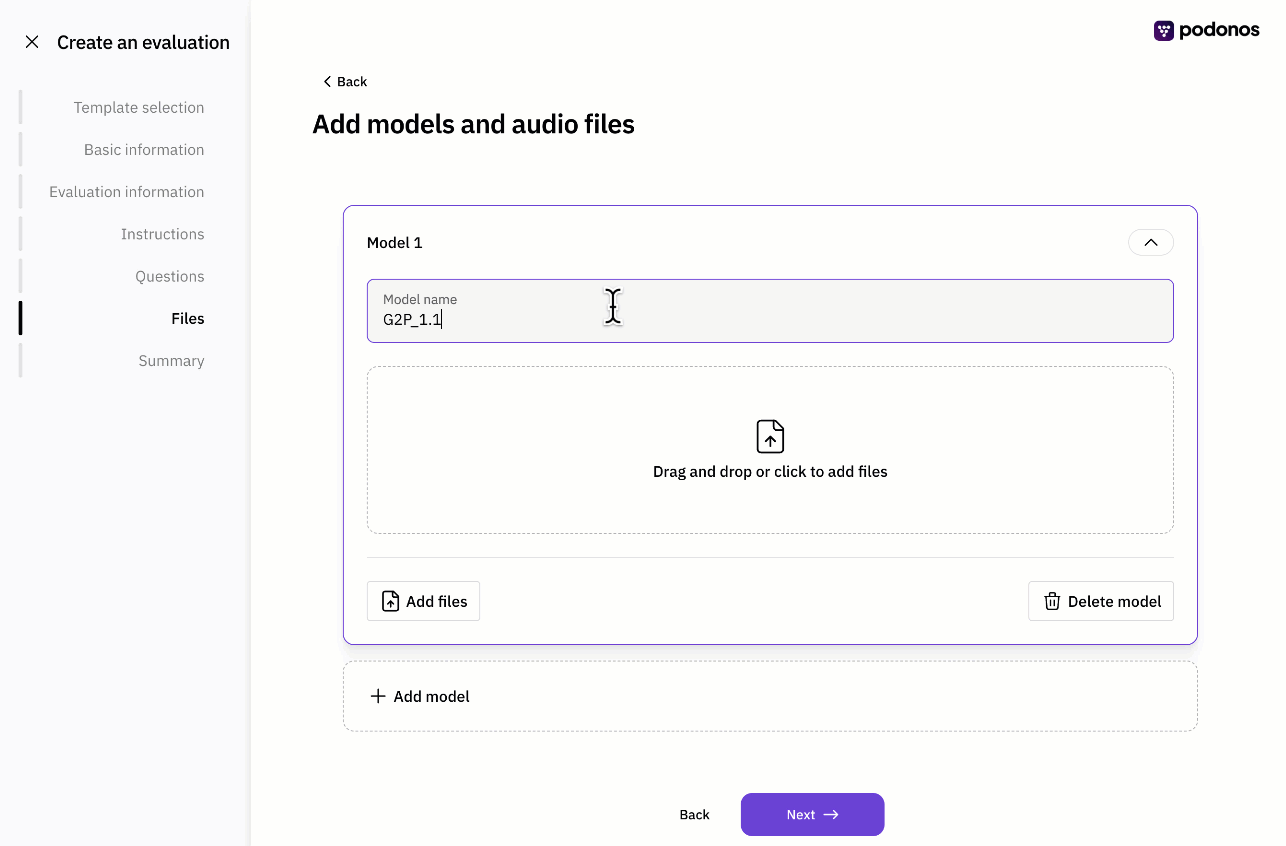
Evaluation template support
You create the template once, use it multiple times. Once you create your own template, you can re-use them in the following evaluations.New Billing & Payment
We have a new look in the Billing & Payments. You can set up the recurring payments and get additional discounts.High Scalability
You can evaluate up to 10k queries with 10k files in a single session.Nov 2024
Workspace is revamped
Now, the workspace has a new look and a more organized menu.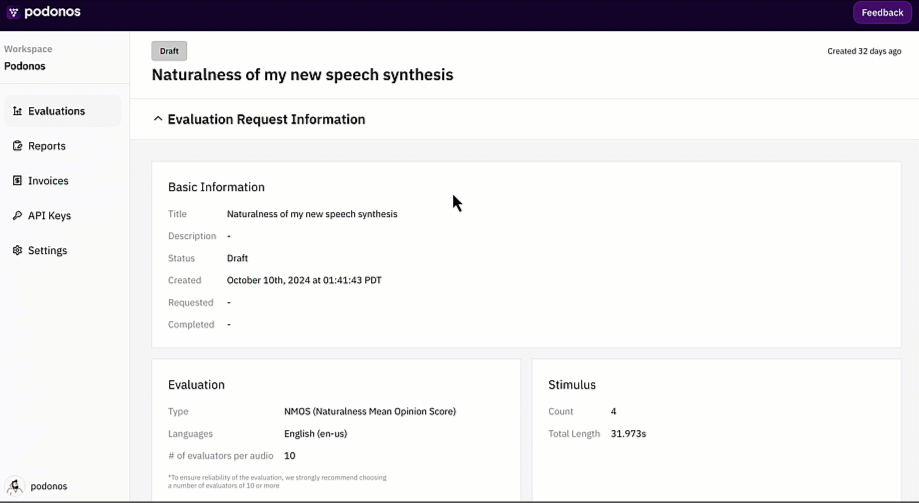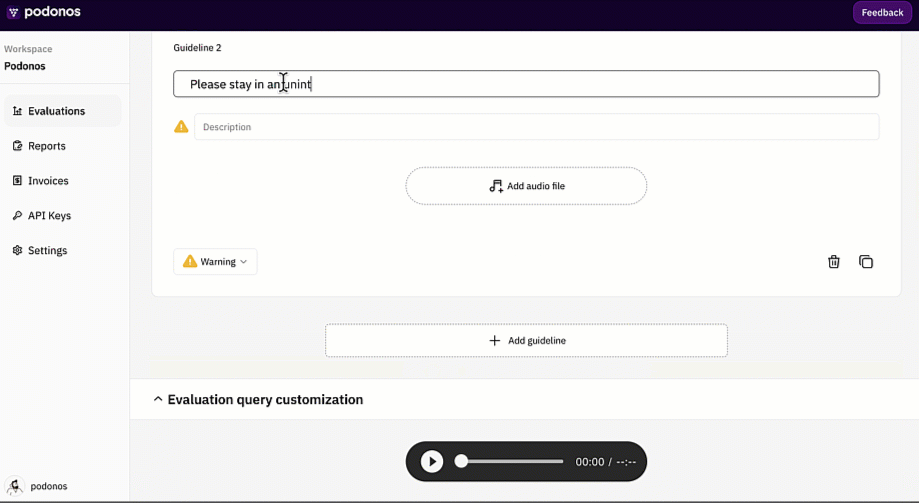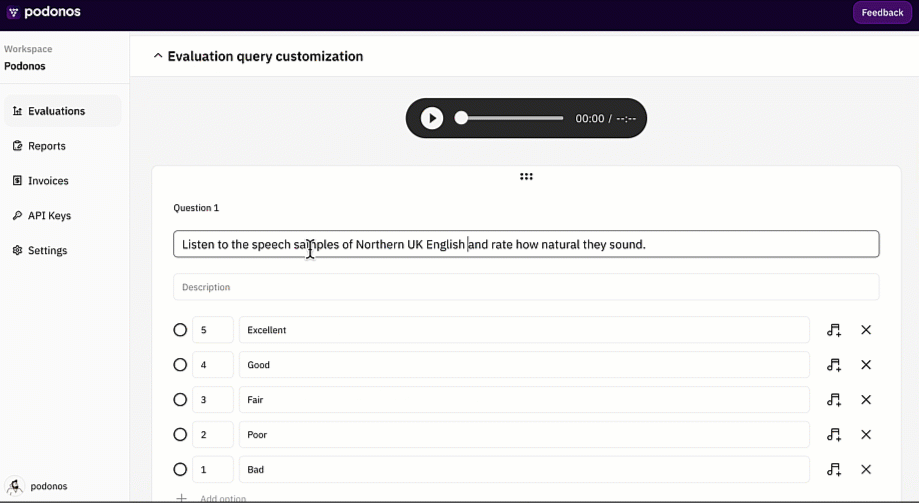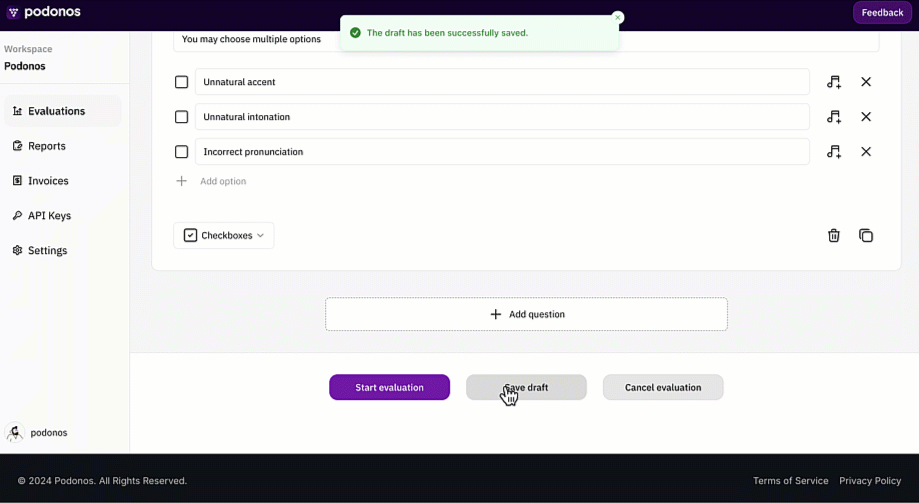
Fully customize your own evaluations
So far, you can use the provided evaluation templates. Now, you can add your own messages and followup questions up to 8. Instead of asking a single question, you can ask multiple questions on different types.Add audio examples
Evaluator may wonder what is excellent and what is bad. You can add audio examples, so your evaluation will be more consistent.New format support
We now support FLAC type too in addition to wav and mp3.Sep 2024
New evaluation report
We revamped the whole report presentation. With the new concept ofmodel_tag, you can group the evaulations into models and multiple tags and analyze more details.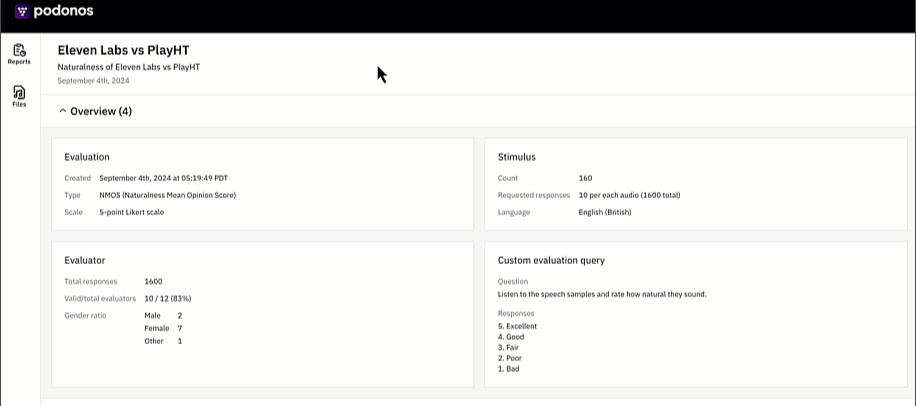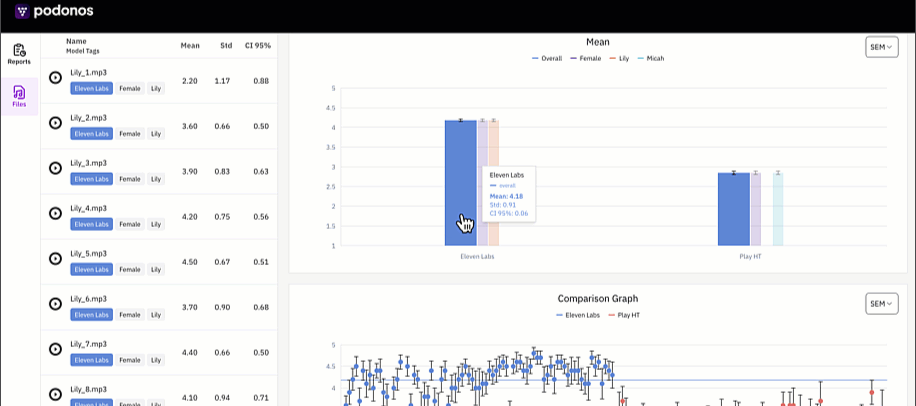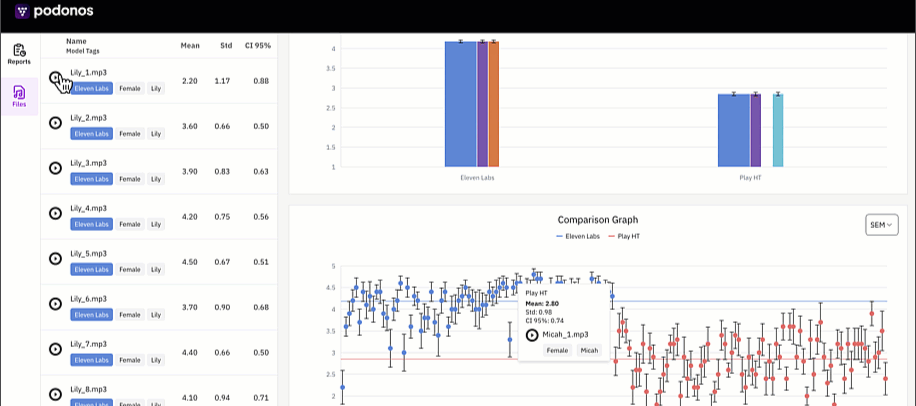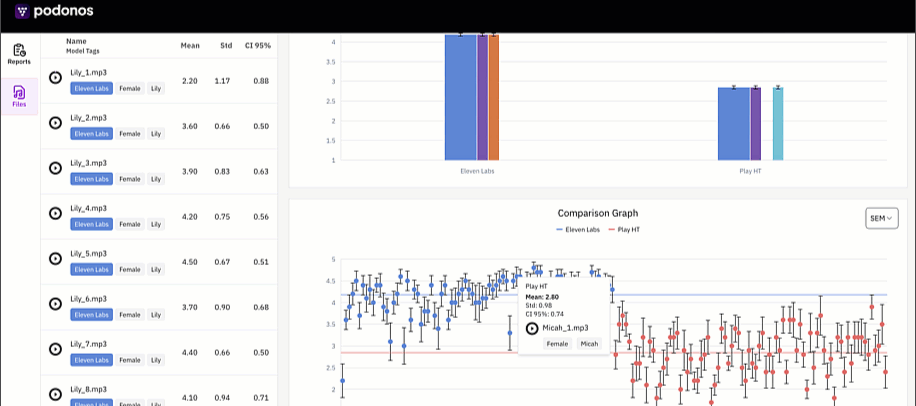
Reasoning behind the rating
One of the core questions behind the report is that “why did the evaluator think so?”.So we added this new feature to ask the evaluators to annotate the words/phrases and put reasons behind the evaluation ratings.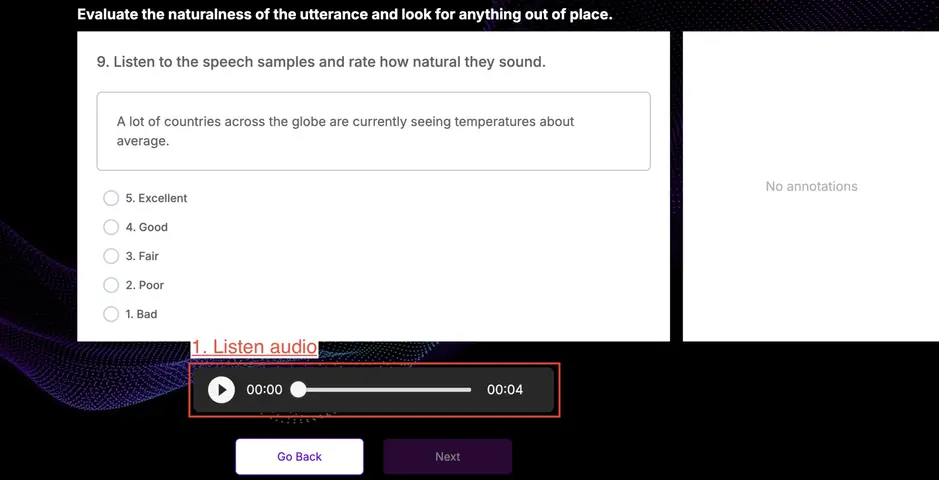
6x faster upload in SDK
We previously made the file upload 2x faster. Again, we have made 6x faster upload, total 12x faster than last month.It can be faster depending on your internet speed.SDK documentation updated
We have revamped the whole SDK documents with more detailed descriptions and examples.Many more stability and bug fixes
We have fixed multiple performance and stability issues. Also fixed many bugs for more accurate evaluations.Aug 2024
Custom question and detailed description
You can customize the question and the detailed description - So you can ask your own question to the evaluators instead of ours.2x faster file upload
Our backend service has become faster and the SDK uploads your files to evaluate in multiple upload sessions.Add the API key to the environment variable
See this document for details.In addition, we have tons of ideas around evaluation management, reliability, modality, speed improvement, and so on. If you have cool ideas, please feel free to let us know at hello@podonos.com.