Audio Deepfake Detection Benchmark: the production bar moves to four

When we published this benchmark last month, two commercial systems sat alone above 95% accuracy and everything else trailed by double digits. Just a few weeks later, with nine new systems added, the picture has changed in a way worth reporting. The top of the field is now crowded, the open-source gap is wider than ever, and speed has become a real differentiator.
We expanded the benchmark from 8 detectors to 17. The new entries include four commercial APIs (Whispeak, Pindrop, Corsound AI, Synhawk) and five more open-source baselines, among them models trained on the newer ASVspoof 5 and VoxCelebSpoof corpora. The test set, the private labels, and the scoring are unchanged, so every number below is directly comparable to the first release.
Why a private benchmark? Vendors routinely self-report around 99% accuracy on their own test sets. Those numbers aren't comparable and are easy to overfit. We hold a fixed evaluation set of 4,524 clips with private gold-standard labels and score every system the same way: real audio vs. modern commercial voice clones, across six file formats.
The leaderboard
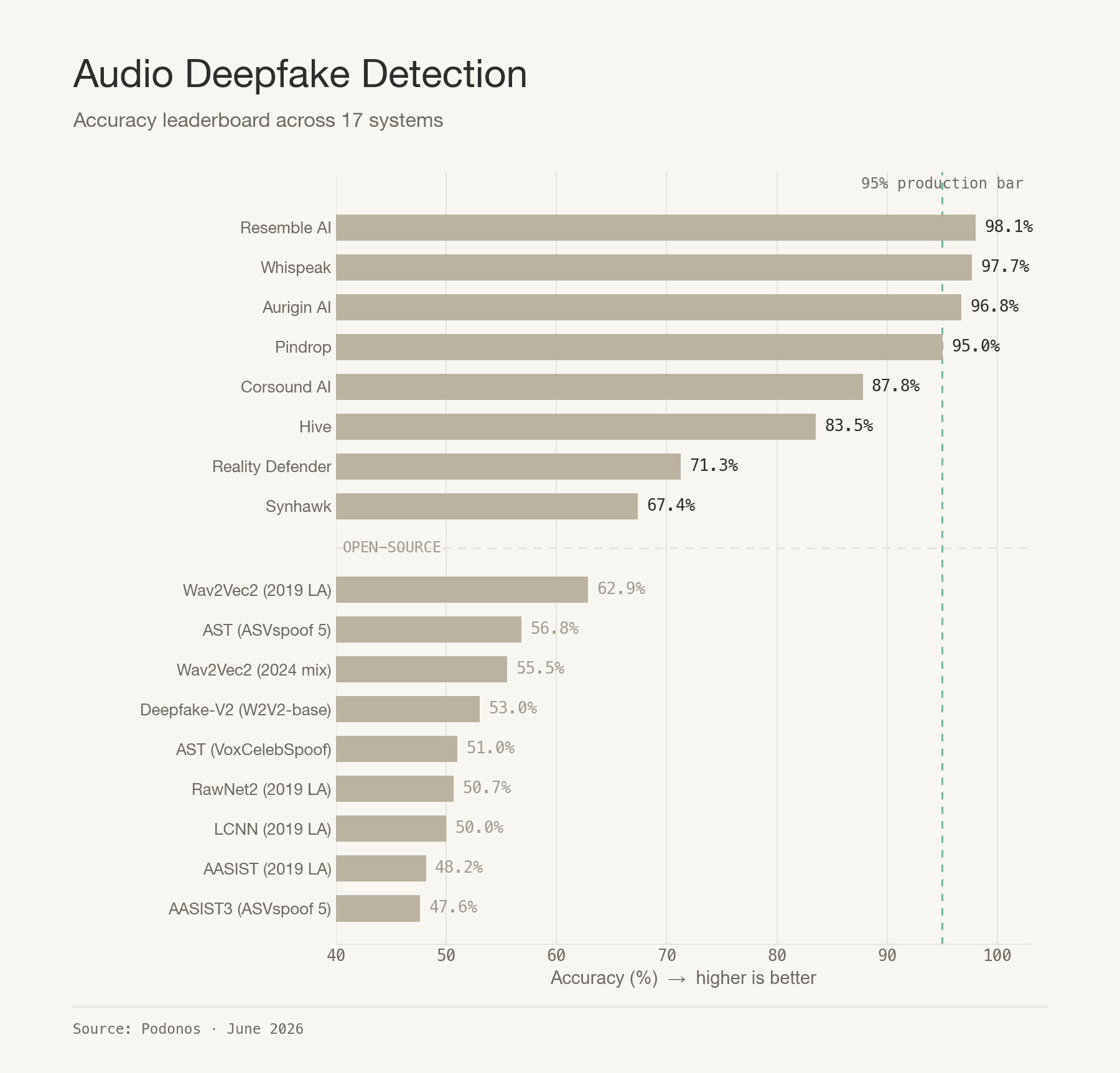
Commercial APIs are in bold. N is 4,524 for every system except Corsound (3,875) and Reality Defender (3,745), which reject short clips. Per-format breakdowns and reproduction code live in the public repository.
Four systems now clear 95%
Last time, Resemble AI and Aurigin AI were the only systems above 95%. Now there are four, and the newcomer between them is the headline.
Whispeak debuts at #2 (97.70%) with the most balanced error profile in the field: 2.9% false positives, 1.7% false negatives. It doesn't lean toward over- or under-flagging. It's simply strong on both real and fake audio.
Resemble AI still leads (98.05%) and remains the best at catching fakes (1.4% false-negative rate, roughly 1 missed deepfake in 70).
Aurigin AI (96.75%) holds the lowest false-positive rate among systems that also catch fakes (1.5%), making it the safest choice when wrongly flagging real audio is the expensive mistake.
Pindrop (95.05%) squeaks over the bar, and rewrites the speed story (more below).
The takeaway for buyers hasn't changed, only sharpened. At the top, the decision is no longer "who's accurate" but "which error can you least afford?" All four are production-grade; they differ in whether they'd rather miss a fake or false-alarm on a real voice.
Speed is now a differentiator

Real-Time Factor (RTF) is processing time divided by audio duration, where below 1.0 is faster than real-time. Adding Pindrop made speed a story in its own right:
Pindrop is the fastest accurate detector by a wide margin, at roughly 282 ms per file and an RTF of 0.076. That is about 4x faster than Resemble and Whispeak (RTF around 0.40) and roughly 20x faster than Reality Defender.
Reality Defender is the only system slower than real-time (RTF 1.52): a 5-second clip takes about 7.6 seconds to score. It sits alone in the "fails real-time" zone and is not viable for streaming.
Everyone else lands comfortably under RTF 0.4, well inside real-time budgets.
If you're scoring audio inline, for live calls or streaming moderation, the top-right of the leaderboard and the left edge of this chart are where to look.
The real choice is an error trade-off
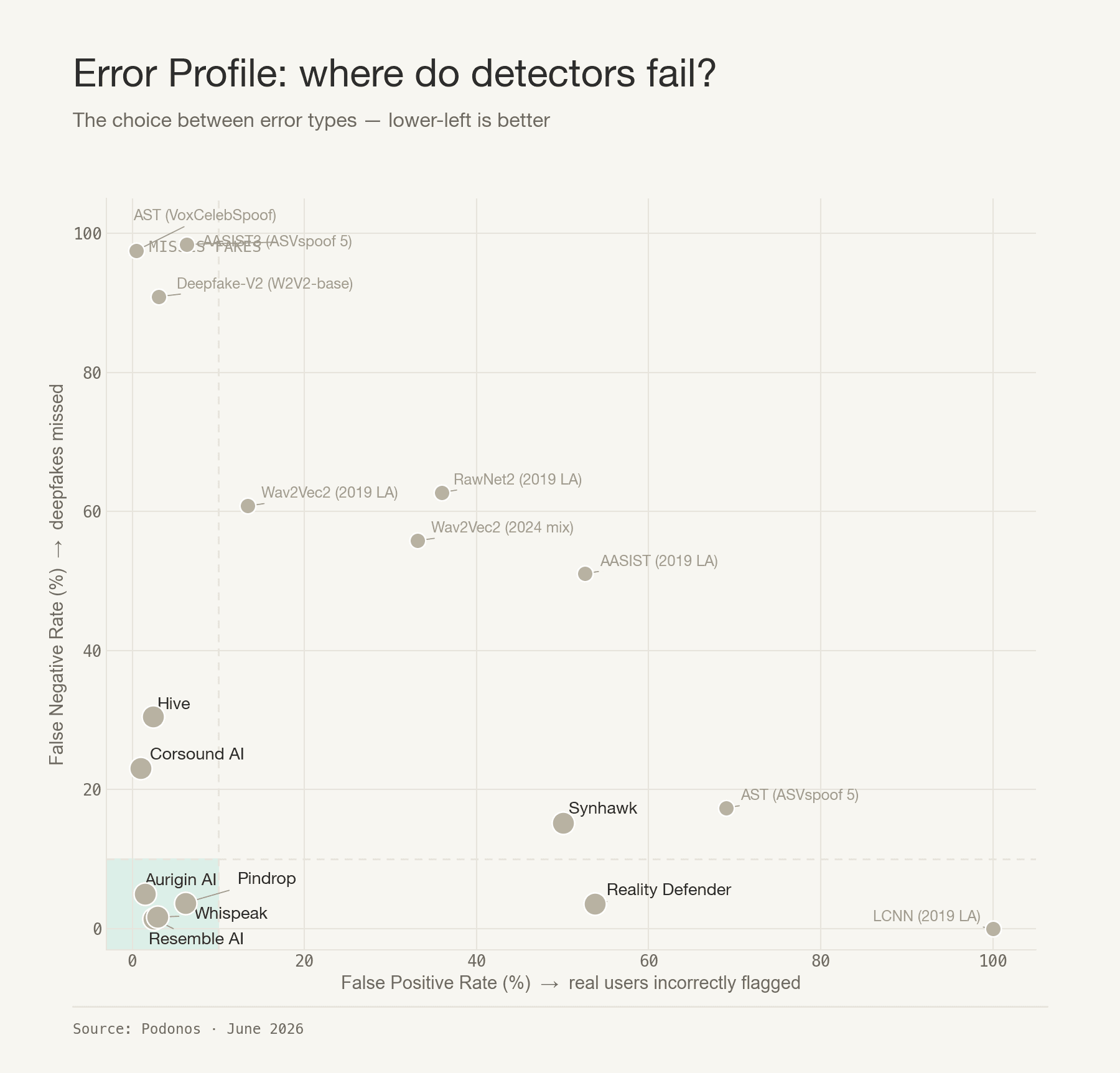
Headline accuracy hides how a detector fails. Plotting false-positive rate (flagging real audio as fake) against false-negative rate (missing a deepfake) separates the field cleanly, and lower-left is better:
The good corner is crowded by the top four. Resemble, Whispeak, Aurigin, and Pindrop all keep both error types low.
Corsound AI and Hive are conservative, with very low false positives (1.0% and 2.4%) but high miss rates (23% and 31%). They rarely cry wolf, but let a meaningful share of fakes through.
Reality Defender and Synhawk have the opposite problem. Both flag roughly half of all real audio as fake (FPR 53.7% and 50.0%). They are strong on fakes, but carry unusable false-alarm rates on genuine voices.
Open-source still doesn't generalize, even the newer models
This is the result we most wanted to retest. Last time we showed that open-source detectors trained on the older ASVspoof 2019 LA corpus scored near chance. The obvious question: do the newer academic models, trained on ASVspoof 5 and VoxCelebSpoof, do any better?
They don't. All nine open-source baselines land between 47.6% and 62.9%, regardless of training era. Several collapse to predicting a single class: one flags every clip as fake (100% false-positive rate), while three flag almost everything as real (over 90% miss rate). Their accuracy is an artifact of the 50/50 class balance, not detection skill.
The lesson holds and generalizes. Off-the-shelf academic checkpoints are not a substitute for a production detector against today's commercial voice cloning, and newer training data alone does not close the gap.
Methodology
4,524 audio clips, balanced 50/50 real vs. synthetic.
Real audio from VCTK, LJSpeech, and LibriTTS-360.
Synthetic audio from about 25 modern TTS and voice-cloning systems (ElevenLabs, Microsoft F5-TTS, Chatterbox, and more), each round-trip verified with Whisper transcription before inclusion.
Six file formats (mp3, wav, flac, ogg, m4a, webm) to test robustness across real-world distribution channels.
Private labels. Default thresholds for every system, no per-tool tuning, no cherry-picking formats. We report error modes and rejection rates, not just top-line accuracy. We deliberately omit Equal Error Rate, which assumes an oracle threshold you can't set in production.
Submit your system
The benchmark is open. To be scored against the private gold standard, run your detector over the public dataset and produce a predictions.csv with three columns: filename, label (real or fake), and latency_ms.
Email it to hello@podonos.com and we'll add you to the leaderboard. The dataset and reproduction scripts are in the public repository.
Limitations
The benchmark is English-only and is a snapshot of a fast-moving TTS landscape; as new generators ship, the test set will need to keep pace. Latency and RTF are measured under our conditions and will vary with region, network, and batch size. Synhawk did not return latency data in this run, so it is omitted from the speed chart.
Other readings

Natural ≠ Preferred: What Our TTS Rankings Revealed About How Humans Actually Judge AI Voices
Quickly uncover deep insights into your voice AI's strengths and drive faster development, smarter marketing, and flawless delivery.
|
7 min read

Automatic Deepfake Audio Detection Benchmark
Quickly uncover deep insights into your voice AI's strengths and drive faster development, smarter marketing, and flawless delivery.
|
7 min read

Announcing the Selected Teams for the Podonos Research Support Program
Quickly uncover deep insights into your voice AI's strengths and drive faster development, smarter marketing, and flawless delivery.
|
2 min read

Benchmarking Chatterbox Turbo: How Resemble AI Evaluated Open-Source Voice AI with Podonos
Quickly uncover deep insights into your voice AI's strengths and drive faster development, smarter marketing, and flawless delivery.
|
5 min read

Introducing Podonos Flash
Quickly uncover deep insights into your voice AI's strengths and drive faster development, smarter marketing, and flawless delivery.
|
4 min read

Podonos just raised $2.4M in pre-seed funding
Quickly uncover deep insights into your voice AI's strengths and drive faster development, smarter marketing, and flawless delivery.
|
3 min read

Product Update: Podonos Wizard launch
Quickly uncover deep insights into your voice AI's strengths and drive faster development, smarter marketing, and flawless delivery.
|
2 min read

Why Post-Refining Matters in Voice AI: Making Sense of Raw Evaluation Data
Quickly uncover deep insights into your voice AI's strengths and drive faster development, smarter marketing, and flawless delivery.
|
2 min read

Prescreening Human Evaluators: The First Step Toward Reliable Voice AI Evaluation
Quickly uncover deep insights into your voice AI's strengths and drive faster development, smarter marketing, and flawless delivery.
|
3 min read

Beyond English: Expanding TTS Evaluation into Multi-languages
Quickly uncover deep insights into your voice AI's strengths and drive faster development, smarter marketing, and flawless delivery.
|
2 min read