Intro
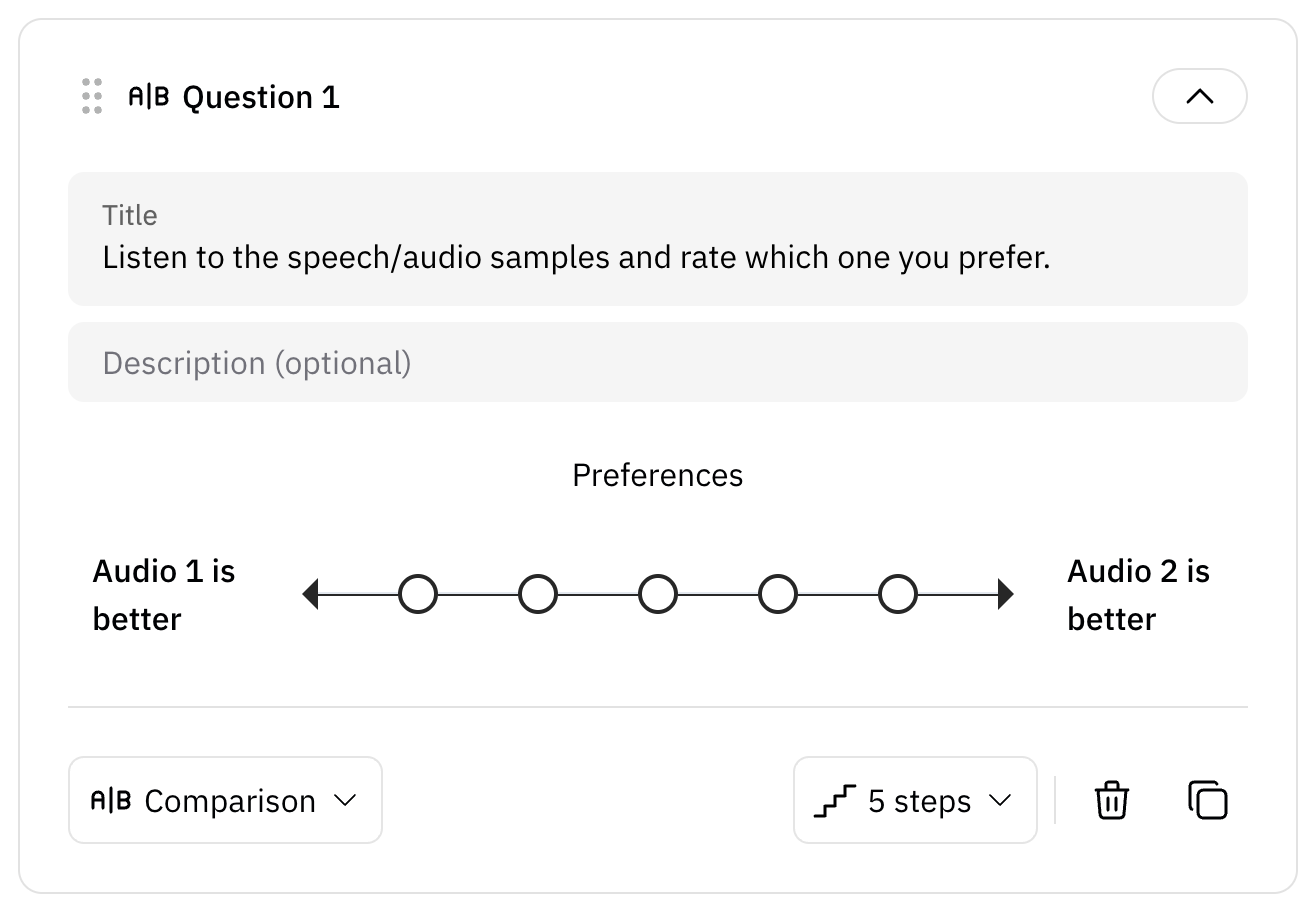
An effective way of evaluating subjective preferences between two pieces of speech or audio is the preference test. This evaluation helps to determine which of the two audio samples is more favored by evaluators. The Preference Test uses a scale to capture listener preferences, typically ranging from -2 to 2, with 1 granularity. The scale is as follows:- 2: A is strongly preferred
- 1: A is preferred
- 0: About the same
- -1: B is preferred
- -2: B is strongly preferred